\n
## Heatmap Pair: Model Performance Comparison (Probe vs. LoRA + Prompt)
### Overview
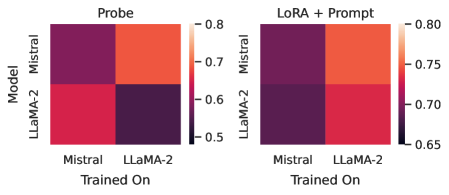
The image displays two side-by-side heatmaps comparing the performance of two machine learning models (Mistral and LLaMA-2) under two different adaptation methods: "Probe" (left) and "LoRA + Prompt" (right). The heatmaps visualize a performance metric (likely accuracy or a similar score) based on which model was used for training and which model is being evaluated.
### Components/Axes
* **Chart Type:** Two 2x2 heatmaps.
* **Y-Axis (Vertical):** Labeled **"Model"**. The two categories are **"Mistral"** (top row) and **"LLaMA-2"** (bottom row). This axis represents the model being evaluated or probed.
* **X-Axis (Horizontal):** Labeled **"Trained On"**. The two categories are **"Mistral"** (left column) and **"LLaMA-2"** (right column). This axis represents the model on which the training or adaptation was performed.
* **Color Scale/Legend:**
* **Left Heatmap (Probe):** A vertical color bar on the right side of the heatmap. The scale ranges from **0.5** (dark purple/black) to **0.8** (bright orange/red). Intermediate markers are at **0.6** and **0.7**.
* **Right Heatmap (LoRA + Prompt):** A vertical color bar on the right side. The scale ranges from **0.65** (dark purple) to **0.80** (bright orange/red). Intermediate markers are at **0.70** and **0.75**.
* **Titles:** The left heatmap is titled **"Probe"**. The right heatmap is titled **"LoRA + Prompt"**.
### Detailed Analysis
**Left Heatmap: "Probe"**
* **Cell (Mistral Model, Trained On Mistral):** Color is a medium-dark purple. Estimated value: **~0.65**.
* **Cell (Mistral Model, Trained On LLaMA-2):** Color is bright orange-red. Estimated value: **~0.78**.
* **Cell (LLaMA-2 Model, Trained On Mistral):** Color is a bright red-pink. Estimated value: **~0.75**.
* **Cell (LLaMA-2 Model, Trained On LLaMA-2):** Color is very dark purple/black. Estimated value: **~0.52**.
**Right Heatmap: "LoRA + Prompt"**
* **Cell (Mistral Model, Trained On Mistral):** Color is dark purple. Estimated value: **~0.68**.
* **Cell (Mistral Model, Trained On LLaMA-2):** Color is bright orange-red. Estimated value: **~0.79**.
* **Cell (LLaMA-2 Model, Trained On Mistral):** Color is dark purple. Estimated value: **~0.67**.
* **Cell (LLaMA-2 Model, Trained On LLaMA-2):** Color is bright red-pink. Estimated value: **~0.76**.
### Key Observations
1. **Cross-Model Training Advantage:** In both adaptation methods, training on a *different* model than the one being evaluated yields significantly higher performance. The brightest cells (highest values) are always in the off-diagonal positions (Mistral model trained on LLaMA-2, and LLaMA-2 model trained on Mistral).
2. **Method Comparison - LLaMA-2 on LLaMA-2:** The most dramatic difference is for the LLaMA-2 model when trained on itself. With the "Probe" method, this is the worst-performing combination (~0.52). With "LoRA + Prompt," it becomes one of the best-performing combinations (~0.76).
3. **Method Comparison - Mistral on Mistral:** The performance for Mistral trained on itself improves slightly from "Probe" (~0.65) to "LoRA + Prompt" (~0.68).
4. **Overall Performance Range:** The "LoRA + Prompt" method appears to have a higher performance floor (minimum ~0.67) compared to the "Probe" method (minimum ~0.52), suggesting it may be a more robust adaptation technique.
### Interpretation
The data suggests a strong **negative transfer or interference** when a model is probed or adapted using only its own pre-trained weights (the diagonal cells in the "Probe" heatmap). This could indicate that the probing method alone is insufficient to elicit good performance from the base model on the target task.
Conversely, the **LoRA + Prompt** method appears to successfully mitigate this issue, especially for LLaMA-2. The technique seems to enable effective **knowledge transfer or adaptation** when applied across different model architectures (the off-diagonal cells), which consistently show high performance. The fact that LLaMA-2's performance on itself jumps so dramatically with LoRA + Prompt implies that this method is particularly effective at unlocking or reorganizing the model's internal knowledge for the given task, whereas simple probing fails to do so.
The consistent high performance of cross-model training (e.g., Mistral model trained on LLaMA-2 data/weights) under both methods is notable. It may suggest that the task benefits from the features or representations learned by a different but related model architecture, or that the training process effectively distills knowledge from one model into another. The "LoRA + Prompt" method seems to refine and stabilize this cross-model transfer, raising the lower bound of performance.