## Heatmap: Model Performance Comparison (Probe vs LoRA + Prompt)
### Overview
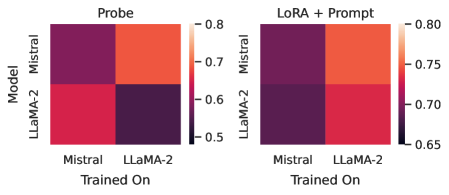
The image contains two side-by-side heatmaps comparing model performance metrics. The left heatmap is labeled "Probe," and the right is labeled "LoRA + Prompt." Both heatmaps evaluate two models ("Mistral" and "LLaMA-2") trained on two datasets ("Mistral" and "LLaMA-2"). Performance is visualized using a color gradient from dark purple (low) to light orange (high), with numerical scales provided.
---
### Components/Axes
- **X-axis (Trained On)**:
- Categories: "Mistral," "LLaMA-2"
- **Y-axis (Model)**:
- Categories: "Mistral," "LLaMA-2"
- **Legend**:
- Color gradient: Dark purple (0.5) → Light orange (0.8 for Probe, 0.75 for LoRA + Prompt)
- Positioned on the right side of each heatmap.
- **Titles**:
- Top heatmap: "Probe"
- Bottom heatmap: "LoRA + Prompt"
---
### Detailed Analysis
#### Probe Heatmap (Left)
- **Mistral (Model) trained on Mistral (Dataset)**: 0.8 (light orange)
- **Mistral (Model) trained on LLaMA-2 (Dataset)**: 0.7 (orange)
- **LLaMA-2 (Model) trained on Mistral (Dataset)**: 0.65 (red)
- **LLaMA-2 (Model) trained on LLaMA-2 (Dataset)**: 0.6 (dark purple)
#### LoRA + Prompt Heatmap (Right)
- **Mistral (Model) trained on Mistral (Dataset)**: 0.75 (orange)
- **Mistral (Model) trained on LLaMA-2 (Dataset)**: 0.7 (red-orange)
- **LLaMA-2 (Model) trained on Mistral (Dataset)**: 0.7 (red-orange)
- **LLaMA-2 (Model) trained on LLaMA-2 (Dataset)**: 0.65 (red)
---
### Key Observations
1. **Probe vs LoRA + Prompt**:
- Probe consistently shows higher performance values across all model/dataset combinations.
- LoRA + Prompt reduces performance slightly (e.g., Mistral on Mistral drops from 0.8 to 0.75).
2. **Model Consistency**:
- Models trained on their native dataset (e.g., Mistral on Mistral) outperform cross-dataset training.
- LLaMA-2 shows the largest performance drop when trained on Mistral (0.65 in Probe, 0.7 in LoRA + Prompt).
3. **Color Correlation**:
- Darker purple (lower values) corresponds to LLaMA-2 trained on Mistral in both heatmaps.
- Light orange (highest values) corresponds to Mistral trained on Mistral in Probe.
---
### Interpretation
The data suggests that model performance is strongly tied to the alignment between training dataset and model architecture. The Probe setup achieves higher scores, indicating that additional LoRA + Prompt techniques may introduce trade-offs in performance. Notably, LLaMA-2 exhibits greater sensitivity to cross-dataset training, with a 0.05 drop in Probe and 0.05 drop in LoRA + Prompt when trained on Mistral. This implies architectural mismatches between models and datasets have a more pronounced impact on LLaMA-2. The consistent color coding across heatmaps reinforces the reliability of these trends.