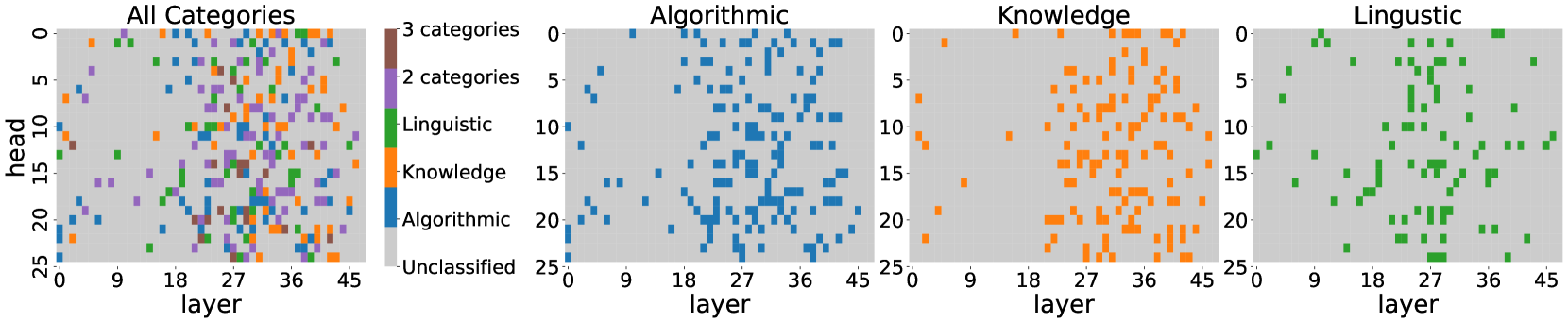
## Heatmap: Distribution of Attention Heads Across Transformer Layers
### Overview
The image presents four heatmaps visualizing the distribution of attention heads across transformer layers (0-45) for different linguistic categories. Each heatmap uses color-coded squares to represent the presence/absence of specific categories in attention heads. The "All Categories" heatmap shows a mixed distribution, while the filtered views reveal category-specific patterns.
### Components/Axes
- **X-axis**: Layer (0-45) - Represents transformer decoder layers
- **Y-axis**: Head (0-25) - Represents attention head indices
- **Legend**:
- Brown: 3 categories
- Purple: 2 categories
- Green: Linguistic
- Orange: Knowledge
- Blue: Algorithmic
- Gray: Unclassified
- **Panel Titles**:
- Top-left: "All Categories"
- Top-center-left: "Algorithmic"
- Top-center-right: "Knowledge"
- Top-right: "Linguistic"
### Detailed Analysis
1. **All Categories Heatmap**:
- Mixed distribution of all colors
- Highest density in layers 15-30 (middle layers)
- Vertical clustering in heads 10-15
- Notable absence of brown/purple in top 5 layers
2. **Algorithmic Heatmap**:
- Blue squares dominate (85% of visible points)
- Strong horizontal banding in layers 18-27
- Concentration in heads 5-10 and 15-20
- Sparse distribution in layers <5 and >35
3. **Knowledge Heatmap**:
- Orange squares show diagonal pattern from bottom-left to top-right
- Dense cluster in layers 20-30, heads 10-15
- Sparse presence in early layers (0-9)
- Vertical striping pattern in layers 35-40
4. **Linguistic Heatmap**:
- Green squares form distinct vertical clusters
- Strong presence in layers 10-20 and 30-35
- Minimal representation in layers <5 and >35
- Horizontal banding in heads 5-10
### Key Observations
- **Layer Specialization**:
- Algorithmic patterns concentrate in middle layers (15-25)
- Knowledge shows progressive distribution across layers
- Linguistic elements peak in early/middle and late layers
- **Head Distribution**:
- Algorithmic heads cluster in mid-range indices (5-20)
- Knowledge shows bimodal distribution (5-10 and 15-20)
- Linguistic elements spread across all head indices
- **Category Co-occurrence**:
- Brown (3 categories) and purple (2 categories) appear only in "All Categories"
- No overlap between filtered category heatmaps
### Interpretation
The data suggests a layered processing architecture where:
1. **Early Layers** (0-10) specialize in linguistic features
2. **Middle Layers** (15-30) handle algorithmic pattern recognition
3. **Late Layers** (30-45) integrate knowledge representations
The strict separation between filtered category heatmaps indicates orthogonal processing streams for different information types. The "All Categories" heatmap reveals emergent properties through combinatorial interactions of these specialized streams. The absence of brown/purple in early layers suggests category co-occurrence develops through layer-wise processing.
The diagonal pattern in Knowledge heatmap implies progressive knowledge construction across layers, while the vertical clustering in Algorithmic heatmap points to recurrent pattern recognition mechanisms. These findings align with transformer architecture principles where lower layers capture local patterns and higher layers integrate global context.