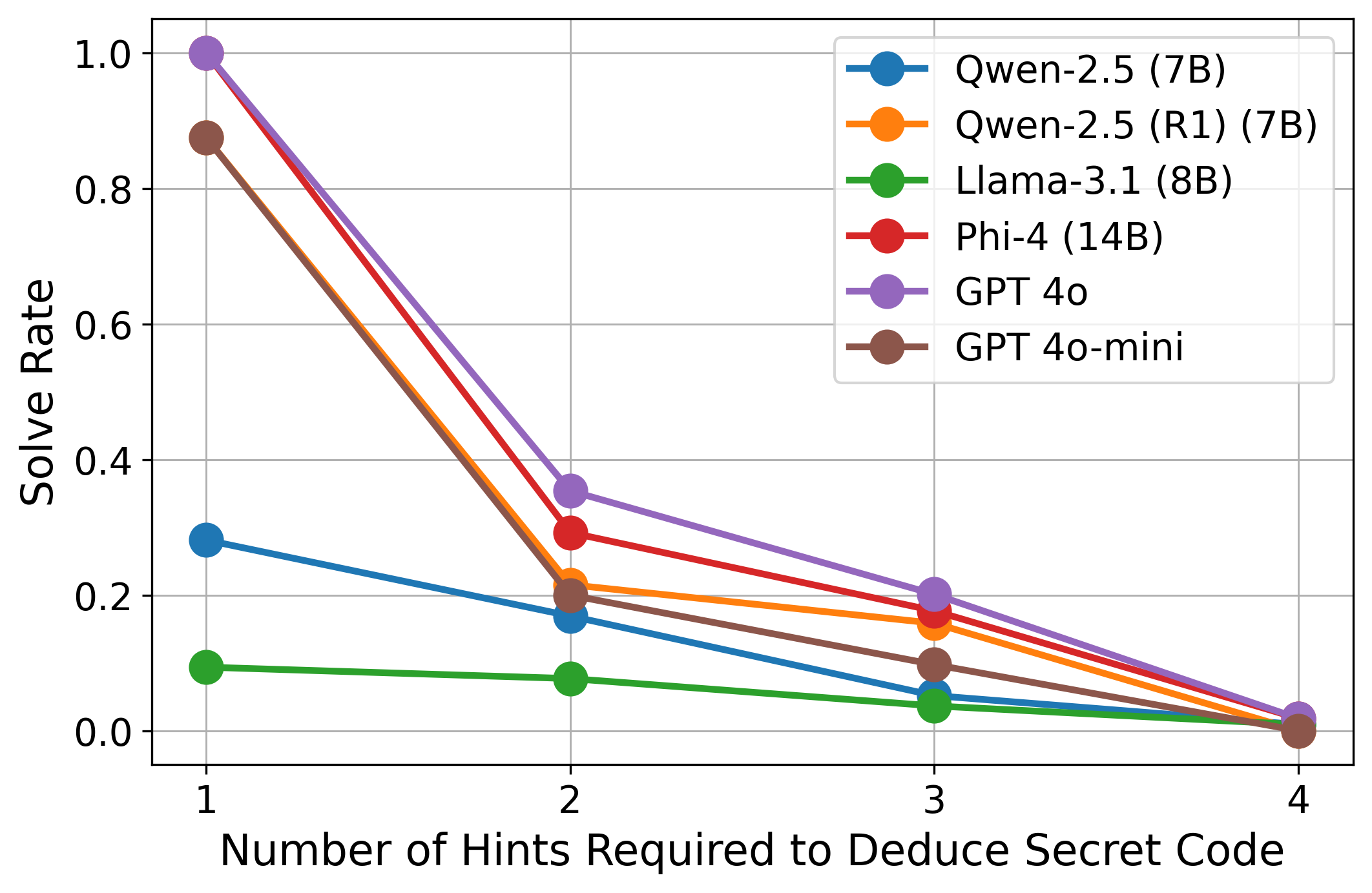
## Line Chart: Solve Rate vs. Number of Hints Required
### Overview
The image is a line chart comparing the solve rates of different language models (Qwen-2.5, Llama-3.1, Phi-4, GPT 4o, and GPT 4o-mini) based on the number of hints required to deduce a secret code. The x-axis represents the number of hints (1 to 4), and the y-axis represents the solve rate (0.0 to 1.0).
### Components/Axes
* **Title:** There is no explicit title on the chart.
* **X-axis:** "Number of Hints Required to Deduce Secret Code" with tick marks at 1, 2, 3, and 4.
* **Y-axis:** "Solve Rate" with tick marks at 0.0, 0.2, 0.4, 0.6, 0.8, and 1.0.
* **Legend:** Located on the top-right of the chart, the legend identifies each line by model name and parameters:
* Blue: Qwen-2.5 (7B)
* Orange: Qwen-2.5 (R1) (7B)
* Green: Llama-3.1 (8B)
* Red: Phi-4 (14B)
* Purple: GPT 4o
* Brown: GPT 4o-mini
### Detailed Analysis
**Data Series Trends and Values:**
* **Qwen-2.5 (7B) (Blue):** The line slopes downward.
* 1 Hint: ~0.29
* 2 Hints: ~0.17
* 3 Hints: ~0.12
* 4 Hints: ~0.01
* **Qwen-2.5 (R1) (7B) (Orange):** The line slopes downward.
* 1 Hint: ~0.88
* 2 Hints: ~0.21
* 3 Hints: ~0.16
* 4 Hints: ~0.01
* **Llama-3.1 (8B) (Green):** The line slopes downward, remaining relatively flat.
* 1 Hint: ~0.10
* 2 Hints: ~0.08
* 3 Hints: ~0.05
* 4 Hints: ~0.01
* **Phi-4 (14B) (Red):** The line slopes downward.
* 1 Hint: ~0.95
* 2 Hints: ~0.29
* 3 Hints: ~0.17
* 4 Hints: ~0.01
* **GPT 4o (Purple):** The line slopes downward.
* 1 Hint: ~1.0
* 2 Hints: ~0.36
* 3 Hints: ~0.20
* 4 Hints: ~0.02
* **GPT 4o-mini (Brown):** The line slopes downward.
* 1 Hint: ~0.87
* 2 Hints: ~0.20
* 3 Hints: ~0.14
* 4 Hints: ~0.01
### Key Observations
* All models show a decrease in solve rate as the number of hints required increases.
* GPT 4o has the highest solve rate with 1 hint, reaching almost 1.0.
* Llama-3.1 (8B) consistently has the lowest solve rate across all hint numbers.
* The solve rates for all models converge to approximately 0.01 when 4 hints are required.
* There is a significant drop in solve rate between 1 and 2 hints for most models.
### Interpretation
The chart illustrates the performance of different language models in solving a task that requires deducing a secret code, based on the number of hints provided. The general trend indicates that as more hints are needed, the solve rate decreases, suggesting that the task becomes more challenging for the models. GPT 4o demonstrates superior initial performance, but all models eventually perform similarly when a larger number of hints is necessary. This could imply that the models are either overfitting to the initial hints or that the complexity of the secret code deduction increases non-linearly with the number of hints. The relatively flat performance of Llama-3.1 (8B) suggests it may struggle with this specific type of task compared to the other models.