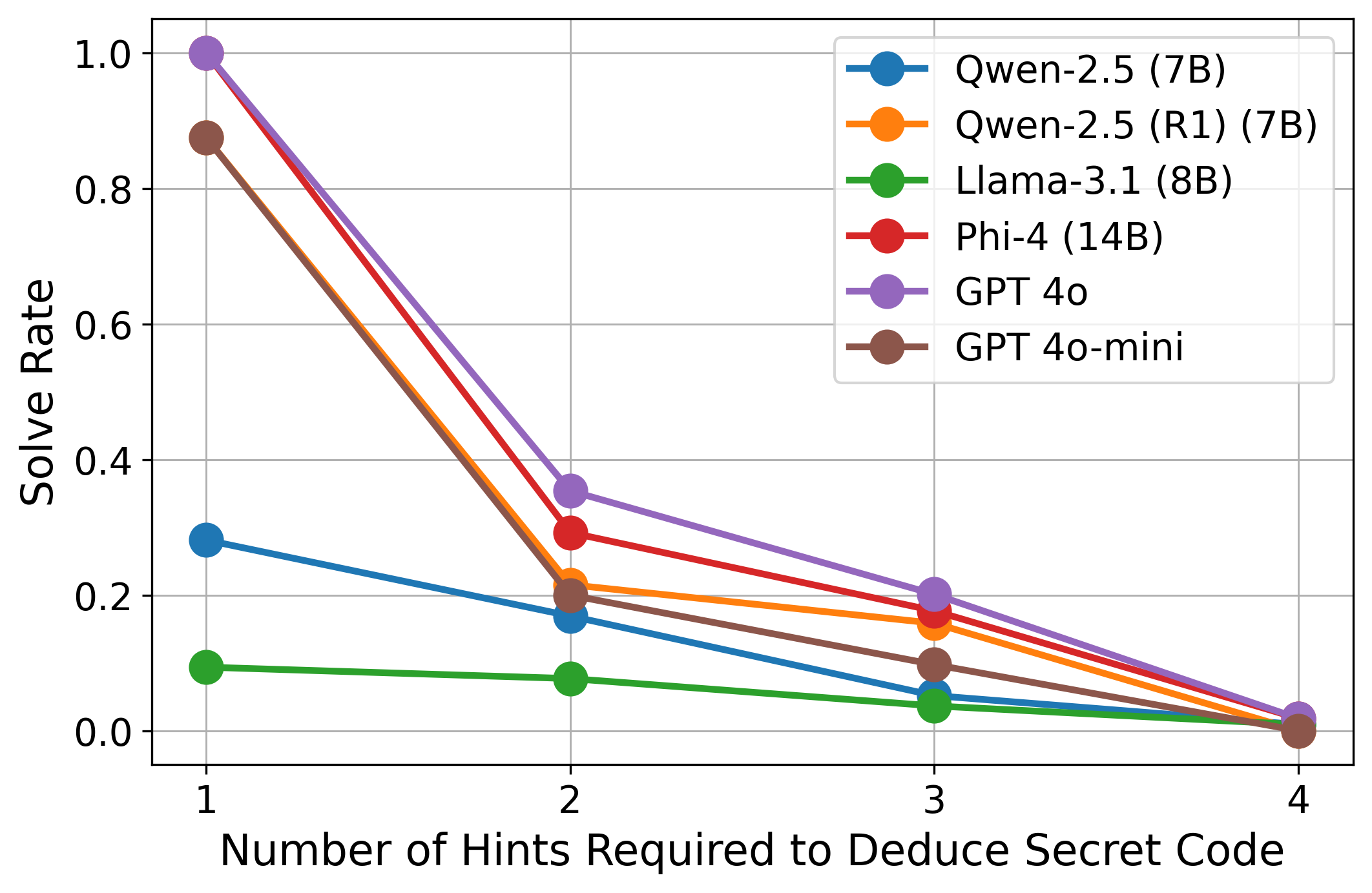
## Line Chart: Solve Rate vs. Number of Hints
### Overview
This line chart depicts the solve rate of several language models (Qwen-2.5, Llama-3.1, Phi-4, GPT-4, and GPT-4o-mini) as a function of the number of hints required to deduce a secret code. The x-axis represents the number of hints (1 to 4), and the y-axis represents the solve rate, ranging from 0.0 to 1.0. Each line represents a different language model, and the legend identifies each line by color.
### Components/Axes
* **X-axis Title:** "Number of Hints Required to Deduce Secret Code"
* **Y-axis Title:** "Solve Rate"
* **Y-axis Scale:** 0.0 to 1.0, with increments of 0.2
* **X-axis Scale:** 1 to 4, with increments of 1
* **Legend:** Located in the top-right corner of the chart.
* Qwen-2.5 (7B) - Blue
* Qwen-2.5 (R1) (7B) - Orange
* Llama-3.1 (8B) - Green
* Phi-4 (14B) - Red
* GPT-4o - Purple
* GPT-4o-mini - Dark Gray
### Detailed Analysis
Here's a breakdown of each line's trend and approximate data points, verified against the legend colors:
* **Qwen-2.5 (7B) - Blue:** The line slopes downward, indicating a decreasing solve rate as the number of hints increases.
* 1 Hint: ~0.25
* 2 Hints: ~0.10
* 3 Hints: ~0.05
* 4 Hints: ~0.02
* **Qwen-2.5 (R1) (7B) - Orange:** The line also slopes downward, but starts at a higher solve rate than Qwen-2.5 (7B).
* 1 Hint: ~0.30
* 2 Hints: ~0.15
* 3 Hints: ~0.10
* 4 Hints: ~0.05
* **Llama-3.1 (8B) - Green:** This line shows a very steep downward slope, starting at a low solve rate.
* 1 Hint: ~0.05
* 2 Hints: ~0.02
* 3 Hints: ~0.01
* 4 Hints: ~0.005
* **Phi-4 (14B) - Red:** This line exhibits the steepest downward slope, starting at a solve rate of approximately 1.0.
* 1 Hint: ~0.95
* 2 Hints: ~0.35
* 3 Hints: ~0.10
* 4 Hints: ~0.02
* **GPT-4o - Purple:** The line slopes downward, starting at a high solve rate.
* 1 Hint: ~0.60
* 2 Hints: ~0.25
* 3 Hints: ~0.15
* 4 Hints: ~0.08
* **GPT-4o-mini - Dark Gray:** The line slopes downward, starting at a solve rate of approximately 0.3.
* 1 Hint: ~0.30
* 2 Hints: ~0.15
* 3 Hints: ~0.08
* 4 Hints: ~0.04
### Key Observations
* Phi-4 (14B) has the highest initial solve rate (at 1 hint) and the most rapid decline as the number of hints increases.
* Llama-3.1 (8B) consistently has the lowest solve rate across all hint levels.
* GPT-4o and GPT-4o-mini perform similarly, with GPT-4o generally having a slightly higher solve rate.
* Qwen-2.5 (7B) and Qwen-2.5 (R1) (7B) show similar trends, with Qwen-2.5 (R1) (7B) performing slightly better.
### Interpretation
The chart demonstrates the ability of different language models to deduce a secret code with varying levels of assistance (hints). The solve rate decreases as the number of hints increases for all models, suggesting that the task becomes easier with fewer hints. The significant difference in performance between Phi-4 (14B) and Llama-3.1 (8B) indicates a substantial gap in reasoning and problem-solving capabilities between these models. The rapid decline in Phi-4's solve rate with each hint suggests it excels at solving the code with minimal information but struggles when more information is provided, potentially due to overfitting or a sensitivity to noise. The relatively stable performance of GPT-4o and GPT-4o-mini suggests a more robust approach to problem-solving. The comparison between Qwen-2.5 (7B) and Qwen-2.5 (R1) (7B) suggests that the R1 revision improves performance, likely through refined training data or architecture. Overall, the chart provides valuable insights into the strengths and weaknesses of different language models in a deductive reasoning task.