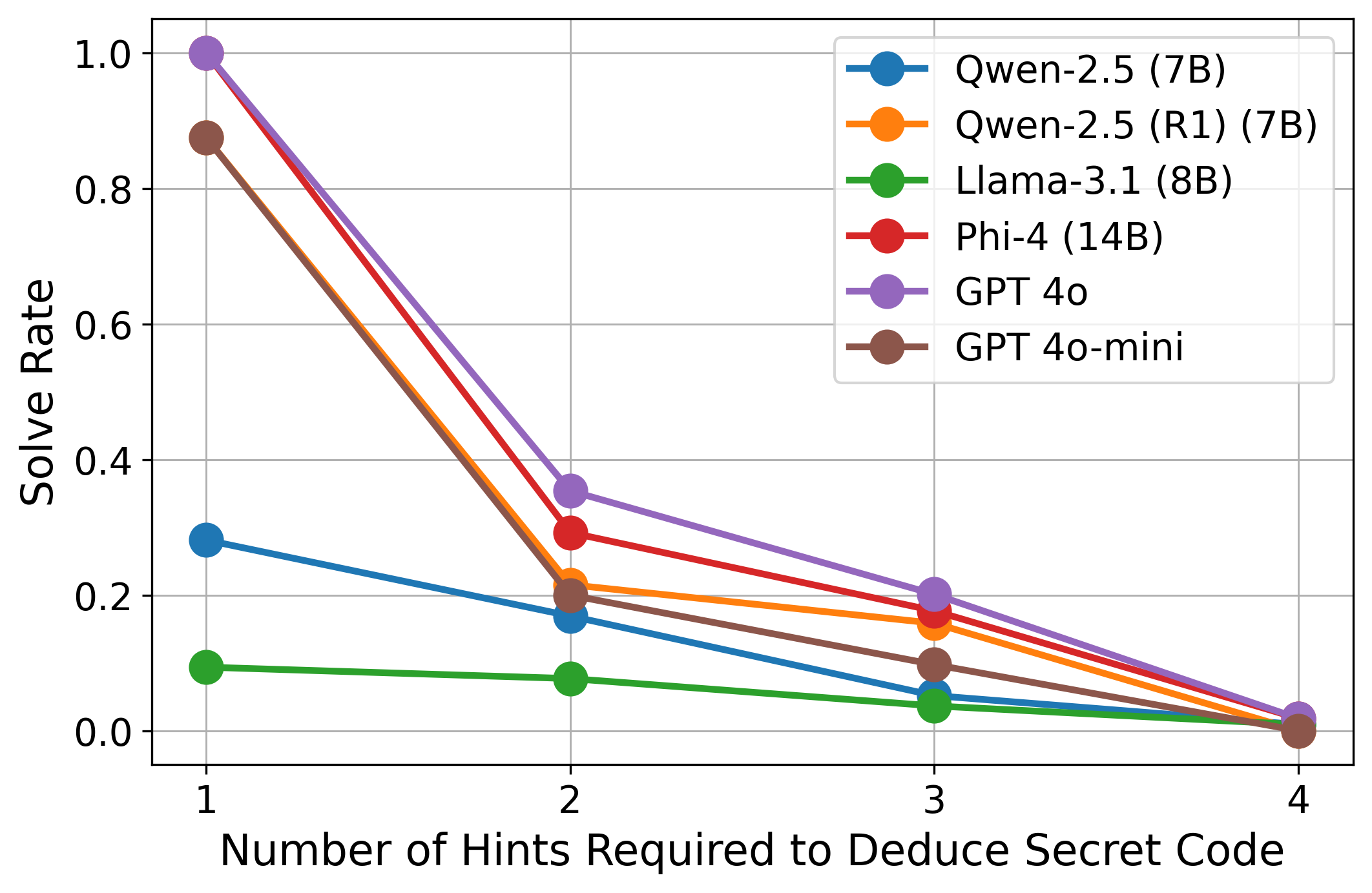
## Line Graph: Solve Rate vs. Number of Hints Required to Deduce Secret Code
### Overview
The image depicts a line graph comparing the solve rates of six AI models as the number of hints required to deduce a secret code increases from 1 to 4. The y-axis represents solve rate (0–1), and the x-axis represents the number of hints (1–4). Each model is represented by a distinct colored line, with performance trends showing how solve rates decline as hints increase.
### Components/Axes
- **X-axis**: "Number of Hints Required to Deduce Secret Code" (1–4, integer increments).
- **Y-axis**: "Solve Rate" (0–1, linear scale).
- **Legend**: Located in the top-right corner, mapping colors to models:
- Blue: Qwen-2.5 (7B)
- Orange: Qwen-2.5 (R1) (7B)
- Green: Llama-3.1 (8B)
- Red: Phi-4 (14B)
- Purple: GPT 4o
- Brown: GPT 4o-mini
### Detailed Analysis
1. **GPT 4o (Purple)**:
- Starts at ~1.0 solve rate for 1 hint.
- Drops sharply to ~0.35 at 2 hints, ~0.2 at 3 hints, and ~0.05 at 4 hints.
- Steepest decline among all models.
2. **GPT 4o-mini (Brown)**:
- Begins at ~0.85 for 1 hint.
- Declines to ~0.2 at 2 hints, ~0.1 at 3 hints, and ~0.02 at 4 hints.
- Follows a similar but less steep trajectory than GPT 4o.
3. **Phi-4 (Red)**:
- Starts at ~0.9 for 1 hint.
- Drops to ~0.3 at 2 hints, ~0.2 at 3 hints, and ~0.05 at 4 hints.
- Slightly outperforms Qwen-2.5 (R1) but lags behind GPT models.
4. **Qwen-2.5 (R1) (7B) (Orange)**:
- Begins at ~0.8 for 1 hint.
- Declines to ~0.25 at 2 hints, ~0.15 at 3 hints, and ~0.03 at 4 hints.
- Outperforms Llama-3.1 but underperforms Phi-4.
5. **Qwen-2.5 (7B) (Blue)**:
- Starts at ~0.3 for 1 hint.
- Declines to ~0.15 at 2 hints, ~0.05 at 3 hints, and ~0.01 at 4 hints.
- Weakest performer among large models.
6. **Llama-3.1 (8B) (Green)**:
- Starts at ~0.1 for 1 hint.
- Declines to ~0.05 at 2 hints, ~0.02 at 3 hints, and ~0.005 at 4 hints.
- Consistently the lowest solve rate across all hint levels.
### Key Observations
- **Inverse Relationship**: All models show a clear inverse relationship between hints and solve rate. More hints correlate with lower solve rates.
- **Performance Hierarchy**: GPT 4o and GPT 4o-mini dominate performance, while Llama-3.1 is the weakest.
- **Divergence at 1 Hint**: GPT 4o achieves near-perfect solve rate (1.0) with 1 hint, while Llama-3.1 struggles even at this level.
- **Convergence at 4 Hints**: Most models approach near-zero solve rates by 4 hints, suggesting diminishing returns from additional hints.
### Interpretation
The data suggests that AI models with larger parameter counts (e.g., GPT 4o, Phi-4) generally outperform smaller models (e.g., Qwen-2.5, Llama-3.1) in solving secret codes with minimal hints. However, as the number of hints increases, all models experience significant performance degradation, implying that hints may reduce the need for intrinsic problem-solving capability. The stark contrast between GPT 4o and Llama-3.1 highlights the impact of model scale and architecture on task efficiency. The sharp decline in solve rates for GPT 4o after 1 hint raises questions about over-reliance on hints or potential overfitting in training data.