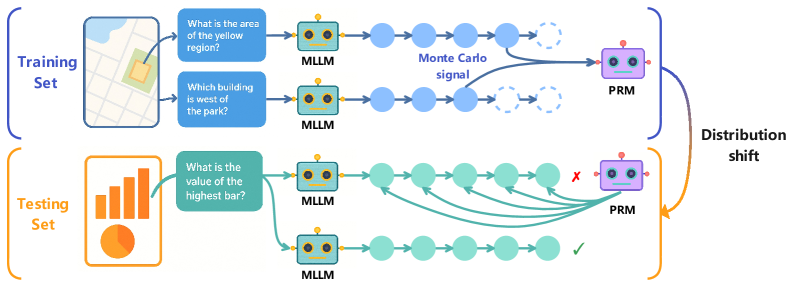
## Diagram: Machine Learning Pipeline with Training and Testing Sets
### Overview
The image is a technical diagram illustrating a machine learning pipeline that processes visual inputs through a Multimodal Large Language Model (MLLM) and a Process Reward Model (PRM). It contrasts the workflow during training versus testing, highlighting a "distribution shift" between the two phases. The diagram uses a flowchart style with icons, text labels, and directional arrows to show data flow and model interactions.
### Components/Axes
The diagram is divided into two primary horizontal sections, each representing a different phase of the machine learning process.
**1. Training Set (Top Section - Blue Theme)**
* **Input:** A map image (top-left) showing a yellow highlighted region and a park.
* **Questions (Blue Boxes):**
* "What is the area of the yellow region?"
* "Which building is west of the park?"
* **Model:** An icon labeled "MLLM" (Multimodal Large Language Model) processes each question.
* **Process Flow:** Each MLLM output is represented by a sequence of blue circles (processing steps). The final step for both sequences is a dashed circle, indicating an incomplete or probabilistic output.
* **Signal:** A curved arrow labeled "Monte Carlo signal" connects the final processing steps of the two MLLM sequences.
* **Evaluation:** The outputs feed into a model icon labeled "PRM" (Process Reward Model).
* **Output:** A blue bracket encompasses this entire section.
**2. Testing Set (Bottom Section - Orange Theme)**
* **Input:** A chart image (bottom-left) containing a bar graph and a pie chart.
* **Question (Green Box):** "What is the value of the highest bar?"
* **Model:** The same "MLLM" icon processes this question.
* **Process Flow:** The MLLM generates two distinct output sequences, represented by two rows of green circles.
* **Evaluation:** Both sequences are evaluated by the "PRM" model.
* **Results:** The top sequence is marked with a red "X" (incorrect). The bottom sequence is marked with a green checkmark (correct).
* **Output:** An orange bracket encompasses this section.
**3. Connecting Element**
* **Label:** "Distribution shift"
* **Visual:** A large, curved orange arrow originates from the PRM in the Training Set section and points to the PRM in the Testing Set section. This indicates that the PRM trained on one data distribution (map-based QA) is being applied to a different distribution (chart-based QA).
### Detailed Analysis
* **Spatial Grounding:** The legend (color-coding) is consistent: Blue elements (questions, processing circles) are associated with the Training Set. Orange elements (input chart, bracket) are associated with the Testing Set. Green elements (question, processing circles) are specific to the testing question's processing flow.
* **Trend Verification:** The diagram does not show numerical trends but illustrates a procedural flow. The trend is the movement of data from input, through the MLLM, to evaluation by the PRM.
* **Component Isolation:**
* **Header/Training Region:** Focuses on training the PRM using multiple, related questions about a single visual input (map), with a "Monte Carlo signal" likely used for reward estimation.
* **Footer/Testing Region:** Focuses on applying the trained PRM to a new visual domain (charts) with a single question, where the PRM must judge the correctness of different MLLM-generated reasoning paths.
* **Text Transcription:** All text is in English. The questions are:
* "What is the area of the yellow region?"
* "Which building is west of the park?"
* "What is the value of the highest bar?"
* Labels: "Training Set", "Testing Set", "MLLM", "Monte Carlo signal", "PRM", "Distribution shift".
### Key Observations
1. **Two-Phase Process:** The system is explicitly designed with separate training and testing phases.
2. **PRM as a Judge:** The PRM's role is to evaluate the quality or correctness of the MLLM's internal reasoning process (the chain of circles), not just the final answer.
3. **Monte Carlo Signal:** This term in the training phase suggests the use of stochastic sampling to estimate rewards or outcomes during training.
4. **Distribution Shift:** This is the central challenge highlighted. The PRM is trained on one type of visual question answering (spatial reasoning on maps) and must generalize to another (data extraction from charts).
5. **Multiple Outputs in Testing:** During testing, the MLLM generates multiple potential reasoning paths for the same question, and the PRM's task is to identify the correct one.
### Interpretation
This diagram illustrates a **reinforcement learning or reward modeling framework for improving multimodal AI reasoning**. The core idea is to train a Process Reward Model (PRM) to act as a verifier or judge.
* **What it demonstrates:** The pipeline aims to make AI reasoning more robust and reliable. Instead of just training a model to produce an answer, it trains a separate model (PRM) to evaluate the *quality of the reasoning steps* that lead to an answer. This is akin to having a teacher who grades not just the final exam answer, but the student's shown work.
* **How elements relate:** The MLLM is the "student" generating answers and reasoning chains. The PRM is the "teacher" or "grader." The "Monte Carlo signal" during training is likely the method used to provide feedback to the PRM on which reasoning paths are good. The "distribution shift" arrow is critical—it shows the system is being tested on its ability to apply learned judgment skills to entirely new problem domains (from maps to charts), which is a key measure of generalization in AI.
* **Notable Implications:** The presence of multiple output paths in the testing phase and the PRM's selection of one as correct suggests this system could be used for **self-improvement or consistency checking**. The MLLM might generate several candidate solutions, and the PRM filters for the most logically sound one. The challenge of distribution shift underscores a major research goal: creating AI systems whose judgment capabilities are not confined to the narrow conditions in which they were trained.