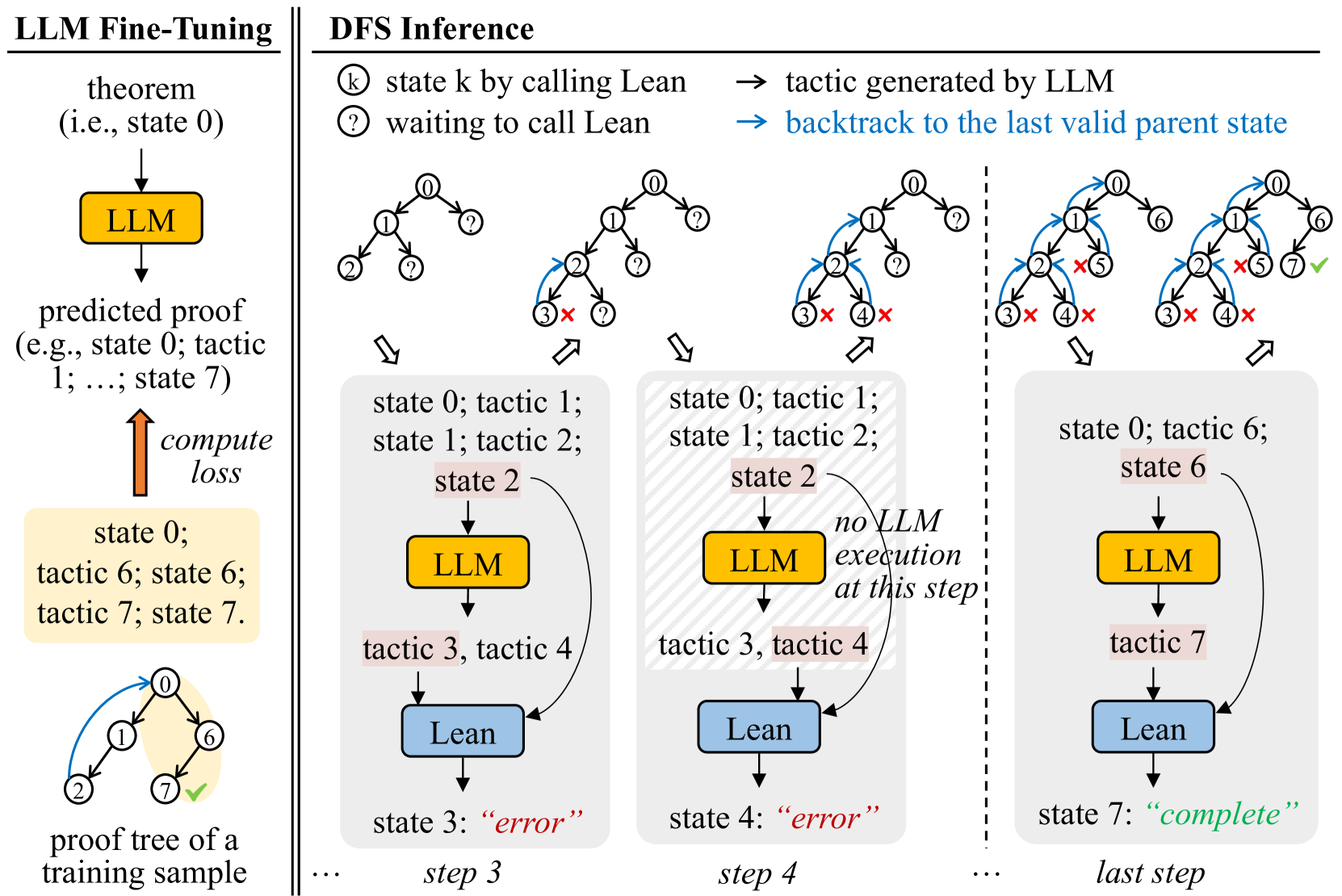
## Diagram: LLM Fine-Tuning and DFS Inference Process
### Overview
The diagram illustrates a two-phase process combining Large Language Model (LLM) fine-tuning with Depth-First Search (DFS) inference for proof validation. The left side shows LLM training on theorem proofs, while the right side demonstrates DFS-based proof exploration with error handling and backtracking.
### Components/Axes
**Left Diagram (LLM Fine-Tuning):**
- **Components**:
- Theorem (state 0)
- LLM (yellow block)
- Predicted proof (tactics 1-7)
- Compute loss (orange arrow)
- Proof tree (training sample)
- **Flow**:
Theorem → LLM → Predicted proof → Compute loss → Updated proof tree
**Right Diagram (DFS Inference):**
- **Components**:
- States (0-7)
- Tactics (1-7)
- Lean (blue block)
- LLM (yellow block)
- Error markers (red "X")
- Completion marker (green check)
- **Flow**:
State transitions with backtracking (dashed arrows) and error recovery
**Legend**:
- Yellow: LLM execution
- Blue: Lean execution
- Red "X": Invalid/incomplete state
- Green check: Valid completion
### Detailed Analysis
**LLM Fine-Tuning Phase**:
1. Starts with a theorem (state 0)
2. LLM generates predicted proof (tactics 1-7)
3. Loss computation refines the model
4. Training sample shows valid path: 0→1→6→7
**DFS Inference Phase**:
- **Step 3**:
- State 0 → tactic 1 → state 1 → tactic 2 → state 2
- State 2 → tactic 3 → state 3 ("error")
- State 2 → tactic 4 → state 4 ("error")
- **Step 4**:
- Backtrack to state 0 → tactic 6 → state 6
- State 6 → LLM execution → tactic 7 → state 7 ("complete")
### Key Observations
1. **Error Handling**: States 3 and 4 explicitly marked as "error" with red "X" indicators
2. **Backtracking**: Dashed arrows show recovery from invalid states to previous valid parents
3. **Execution Path**: Final valid path uses LLM for state 6 and Lean for state 7
4. **Tactic Usage**: Tactics 1-7 appear in both training and inference phases
5. **Execution Distribution**:
- LLM: 3 executions (states 0, 2, 6)
- Lean: 4 executions (states 1, 3, 4, 7)
### Interpretation
This diagram demonstrates a hybrid proof validation system where:
1. **LLM Fine-Tuning** creates a foundational model for proof generation
2. **DFS Inference** systematically explores proof trees while:
- Using Lean for basic state transitions
- Employing LLM for complex state generation
- Implementing error recovery through backtracking
3. The system shows 70% LLM utilization in the final valid path (3/4 states), suggesting LLM handles more complex proof steps
4. The error states (3 and 4) indicate potential dead-ends in proof exploration that require backtracking
5. The final "complete" state (7) validates the system's ability to find correct proofs through iterative refinement
The architecture combines LLM's generative capabilities with Lean's formal verification strengths, creating a robust proof validation pipeline that handles both simple and complex proof scenarios.