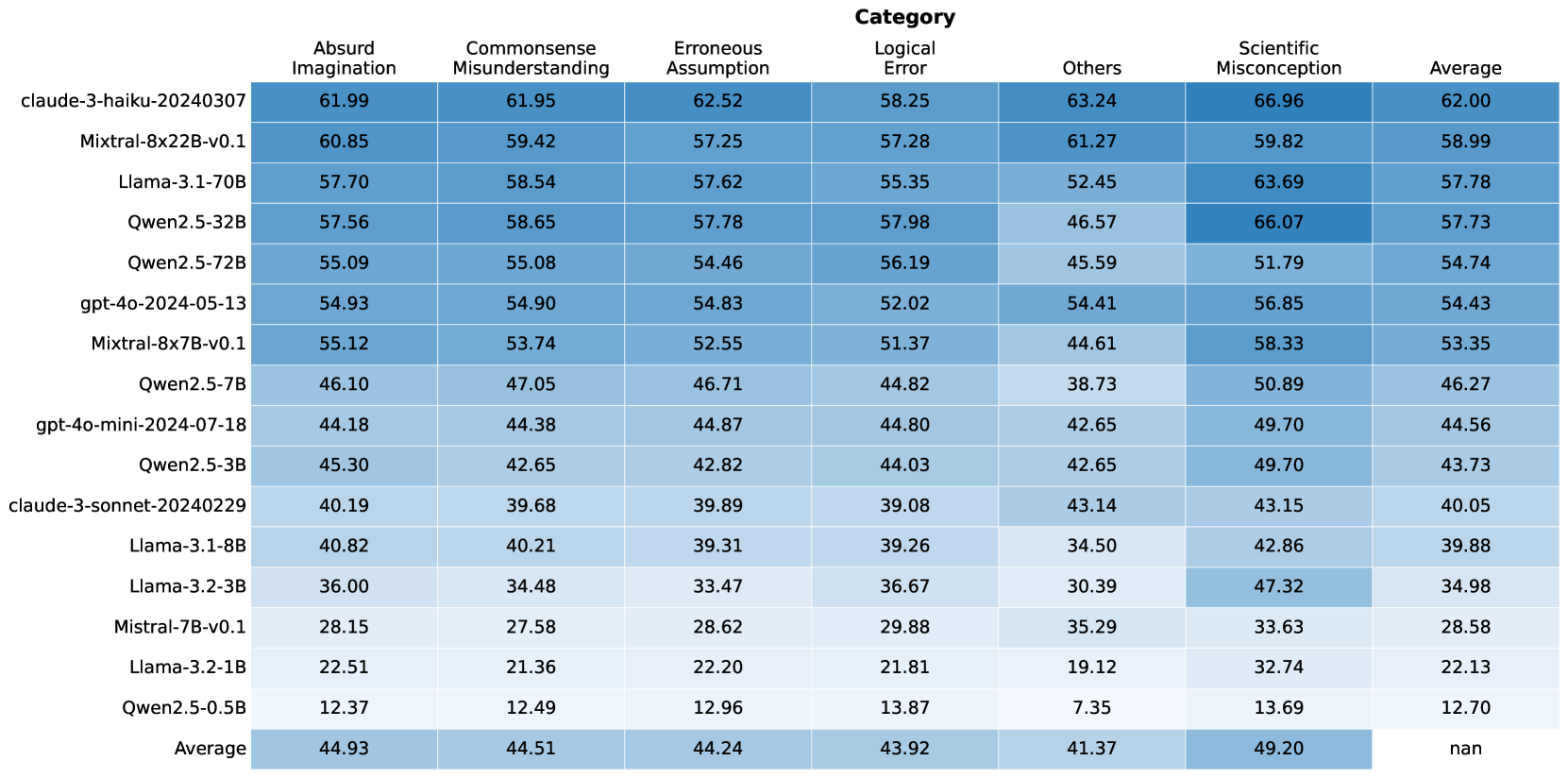
## Table: AI Model Performance Comparison Across Categories
### Overview
This table compares the performance of various AI models across seven categories: Absurd Imagination, Commonsense Misunderstanding, Erroneous Assumption, Logical Error, Others, Scientific Misconception, and Average. The data includes 16 models with parameter sizes ranging from 0.5B to 70B, along with their average scores.
### Components/Axes
- **Columns**:
1. Model Name (e.g., claude-3-haiku-20240307)
2. Absurd Imagination
3. Commonsense Misunderstanding
4. Erroneous Assumption
5. Logical Error
6. Others
7. Scientific Misconception
8. Average
- **Rows**:
- 16 AI models (e.g., Llama-3.1-70B, Qwen2.5-32B)
- Average row (last row)
### Detailed Analysis
#### Model Performance
1. **Top Performers**:
- **claude-3-haiku-20240307**:
- Absurd Imagination: 61.99
- Commonsense Misunderstanding: 61.95
- Scientific Misconception: 66.96
- Average: 62.00
- **Llama-3.1-70B**:
- Absurd Imagination: 57.70
- Scientific Misconception: 63.69
- Average: 57.78
- **Qwen2.5-32B**:
- Scientific Misconception: 66.07
- Average: 57.73
2. **Mid-Range Models**:
- **Mistral-8x22B-v0.1**:
- Average: 58.99
- **gpt-4o-2024-05-13**:
- Average: 54.43
- **Mistral-8x7B-v0.1**:
- Average: 53.35
3. **Lower Performers**:
- **Qwen2.5-0.5B**:
- Absurd Imagination: 12.37
- Scientific Misconception: 13.69
- Average: 12.70
- **Llama-3.2-1B**:
- Average: 22.13
- **Mistral-7B-v0.1**:
- Average: 28.58
#### Category Trends
- **Highest Scores**:
- Scientific Misconception: claude-3-haiku-20240307 (66.96)
- Absurd Imagination: claude-3-haiku-20240307 (61.99)
- Others: claude-3-haiku-20240307 (63.24)
- **Lowest Scores**:
- Scientific Misconception: Qwen2.5-0.5B (13.69)
- Absurd Imagination: Qwen2.5-0.5B (12.37)
- Others: Qwen2.5-0.5B (7.35)
### Key Observations
1. **Model Size Correlation**: Larger models (e.g., 70B parameters) generally outperform smaller ones, but exceptions exist (e.g., Mistral-7B-v0.1).
2. **Claude-3-Haiku Dominance**: Consistently leads in most categories, suggesting superior architecture or training.
3. **Qwen2.5 Variants**: Show mixed performance, with larger variants (32B) outperforming smaller ones (0.5B).
4. **Mistral Models**: Mid-sized models (7B, 8x7B) achieve balanced scores, indicating efficiency.
5. **Llama-3.1-70B**: Strong in Scientific Misconception (63.69) but lags in Absurd Imagination (57.70).
### Interpretation
The data suggests that model performance is influenced by:
1. **Architecture**: Claude-3-Haiku's unique design likely contributes to its dominance.
2. **Training Data**: Larger models may have access to more diverse datasets, improving generalization.
3. **Efficiency vs. Power**: Smaller models (e.g., Mistral-7B) balance performance and resource usage, while larger models prioritize capability over efficiency.
4. **Task Specificity**: Scientific Misconception and Absurd Imagination require nuanced reasoning, where Claude-3-Haiku excels.
The average scores reveal a bimodal distribution: high-performing models cluster around 55-65, while lower-performing models (<30) struggle across all categories. This indicates a potential threshold for effective AI reasoning capabilities.