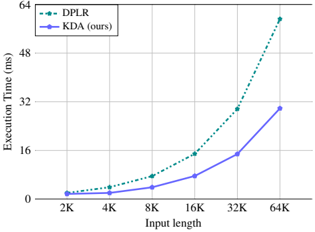
## Line Graph: Execution Time vs. Input Length
### Overview
The image is a line graph comparing the execution time (in milliseconds) of two algorithms, **DPLR** (dashed green line) and **KDA (ours)** (solid blue line), across varying input lengths (2K to 64K). The y-axis represents execution time, and the x-axis represents input length in increments of 2K. The legend is positioned in the top-left corner.
---
### Components/Axes
- **X-axis (Input length)**: Labeled "Input length" with markers at 2K, 4K, 8K, 16K, 32K, and 64K.
- **Y-axis (Execution Time)**: Labeled "Execution Time (ms)" with a range from 0 to 64 ms.
- **Legend**: Located in the top-left corner, with:
- **DPLR**: Dashed green line.
- **KDA (ours)**: Solid blue line.
---
### Detailed Analysis
#### Data Points and Trends
1. **DPLR (dashed green)**:
- **2K**: ~0 ms.
- **4K**: ~2 ms.
- **8K**: ~5 ms.
- **16K**: ~10 ms.
- **32K**: ~20 ms.
- **64K**: ~55 ms.
- **Trend**: Gradual increase until 32K, followed by a steep rise after 32K.
2. **KDA (solid blue)**:
- **2K**: ~0 ms.
- **4K**: ~1 ms.
- **8K**: ~3 ms.
- **16K**: ~6 ms.
- **32K**: ~12 ms.
- **64K**: ~18 ms.
- **Trend**: Steady, linear growth with minimal acceleration.
#### Spatial Grounding
- The legend is anchored in the **top-left** corner, clearly associating colors with labels.
- Data points align with their respective lines: green for DPLR, blue for KDA.
- Gridlines are evenly spaced, aiding in visual alignment of values.
---
### Key Observations
1. **DPLR** exhibits a **non-linear scaling** pattern, with execution time remaining low until 32K input length, then spiking sharply at 64K.
2. **KDA** demonstrates **linear scaling**, maintaining a consistent growth rate across all input lengths.
3. At **64K input length**, DPLR's execution time (~55 ms) is **3x higher** than KDA's (~18 ms).
---
### Interpretation
The graph highlights a critical performance divergence between the two algorithms:
- **DPLR** may be optimized for smaller input sizes but becomes inefficient at larger scales, suggesting potential algorithmic bottlenecks (e.g., memory constraints or suboptimal computational complexity).
- **KDA** scales predictably and efficiently, indicating a more robust design for handling large datasets. This could position KDA as the preferred choice for applications requiring high input lengths with predictable performance.
The stark contrast at 64K input length underscores the importance of algorithmic efficiency in real-world scenarios where data size is a variable factor.