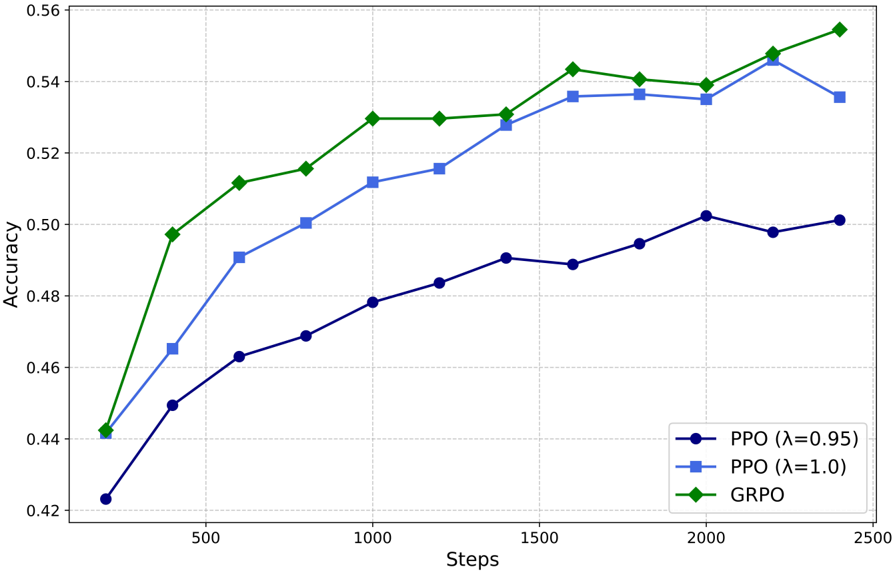
## Line Chart: Accuracy vs. Steps for Different Optimization Methods
### Overview
The chart compares the accuracy of three optimization methods (PPO with λ=0.95, PPO with λ=1.0, and GRPO) across 2500 training steps. Accuracy is measured on a scale from 0.42 to 0.56, with distinct line styles and colors for each method.
### Components/Axes
- **X-axis (Steps)**: Ranges from 0 to 2500, marked at intervals of 500.
- **Y-axis (Accuracy)**: Ranges from 0.42 to 0.56, marked at intervals of 0.02.
- **Legend**: Located in the bottom-right corner, with three entries:
- **Blue circles**: PPO (λ=0.95)
- **Blue squares**: PPO (λ=1.0)
- **Green diamonds**: GRPO
### Detailed Analysis
1. **PPO (λ=0.95)** (Blue circles):
- Starts at **0.422** at 0 steps.
- Gradually increases to **0.502** at 2000 steps.
- Slight dip to **0.500** at 2500 steps.
- Trend: Slow, steady growth with minor fluctuations.
2. **PPO (λ=1.0)** (Blue squares):
- Starts at **0.440** at 0 steps.
- Sharp rise to **0.535** at 2000 steps.
- Slight decline to **0.537** at 2500 steps.
- Trend: Rapid improvement followed by stabilization.
3. **GRPO** (Green diamonds):
- Starts at **0.442** at 0 steps.
- Consistent upward trajectory to **0.555** at 2500 steps.
- Trend: Steady, uninterrupted growth.
### Key Observations
- **GRPO** consistently outperforms both PPO variants, achieving the highest accuracy (0.555) by 2500 steps.
- **PPO (λ=1.0)** surpasses **PPO (λ=0.95)** in both speed and final accuracy.
- **PPO (λ=0.95)** exhibits the slowest growth and lowest final accuracy (0.500).
- All methods show diminishing returns after ~1500 steps, but GRPO maintains momentum.
### Interpretation
The data suggests that **GRPO** is the most effective optimization method for this task, demonstrating superior scalability and final performance. The two PPO variants highlight the impact of the λ parameter: a higher λ (1.0) improves both convergence speed and final accuracy compared to λ=0.95. The slight dip in PPO (λ=0.95) at 2500 steps may indicate overfitting or sensitivity to hyperparameter tuning. GRPO’s uninterrupted growth implies robustness to training dynamics, making it the optimal choice for long-term optimization.