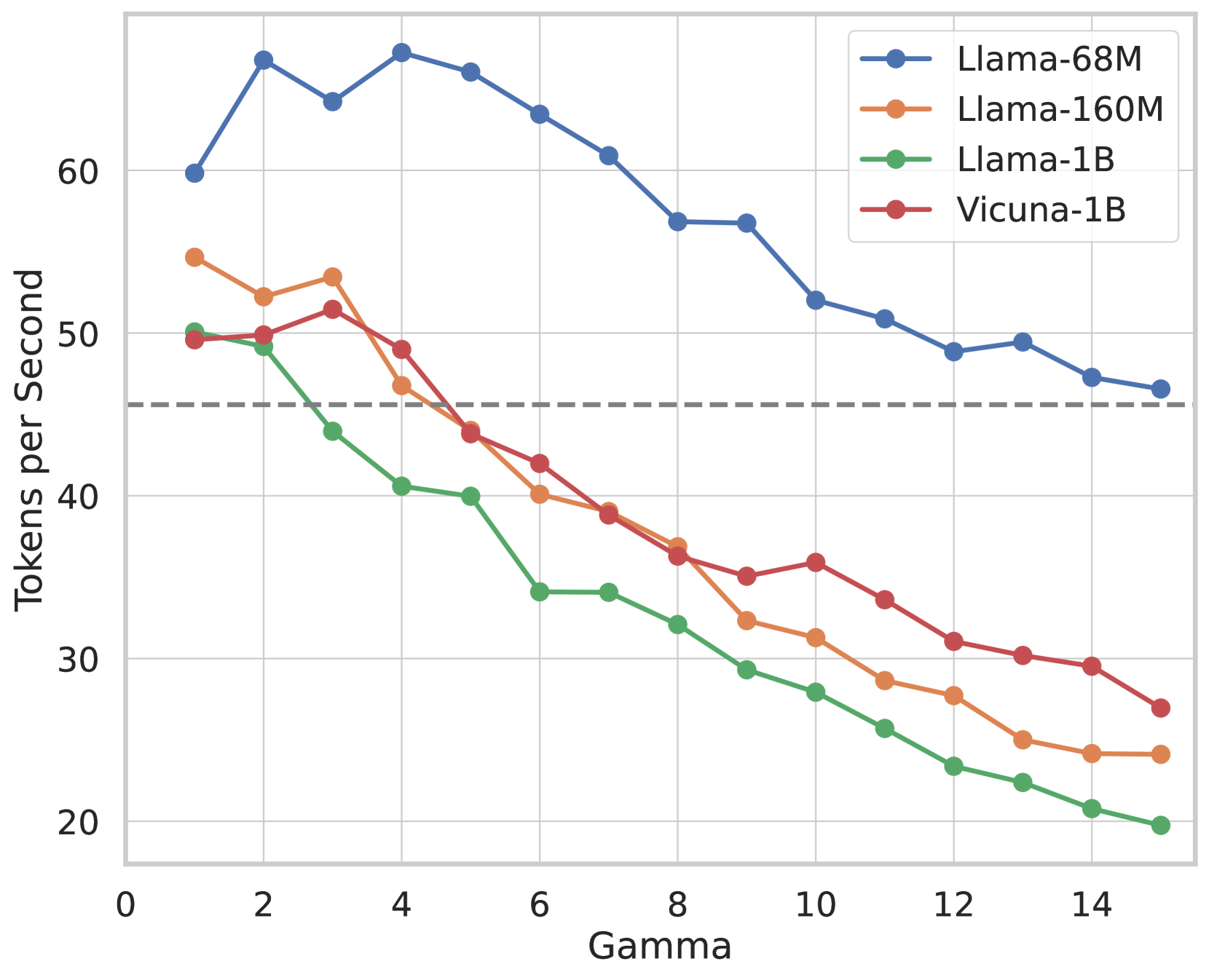
# Technical Data Extraction: Performance Comparison of Llama and Vicuna Models
## 1. Image Overview
This image is a line graph illustrating the relationship between a parameter labeled **"Gamma"** (x-axis) and the processing speed measured in **"Tokens per Second"** (y-axis). It compares four distinct Large Language Model (LLM) configurations.
## 2. Component Isolation
### Header/Legend
* **Location:** Top-right quadrant [x: ~0.7, y: ~0.1].
* **Legend Items:**
* **Blue line with circular markers:** `Llama-68M`
* **Orange line with circular markers:** `Llama-160M`
* **Green line with circular markers:** `Llama-1B`
* **Red line with circular markers:** `Vicuna-1B`
### Main Chart Area
* **X-Axis Label:** `Gamma`
* **X-Axis Scale:** Linear, ranging from `0` to `15` with major tick marks every 2 units (0, 2, 4, 6, 8, 10, 12, 14).
* **Y-Axis Label:** `Tokens per Second`
* **Y-Axis Scale:** Linear, ranging from `20` to `70` (implied higher) with major tick marks every 10 units (20, 30, 40, 50, 60).
* **Reference Line:** A horizontal dashed grey line is positioned at approximately `y = 45.5`.
## 3. Trend Verification and Data Extraction
All four data series exhibit a general **downward trend** as Gamma increases, though the rate of decay and starting performance vary significantly by model size.
### Data Table (Approximate Values)
| Gamma | Llama-68M (Blue) | Llama-160M (Orange) | Vicuna-1B (Red) | Llama-1B (Green) |
| :--- | :--- | :--- | :--- | :--- |
| 1 | ~60 | ~55 | ~50 | ~50 |
| 2 | ~67 | - | - | ~49 |
| 3 | - | ~54 | ~52 | - |
| 4 | ~68 (Peak) | - | - | ~41 |
| 6 | - | ~40 | - | ~34 |
| 7 | - | ~39 | ~39 | - |
| 8 | ~57 | - | - | - |
| 10 | - | ~31 | - | - |
| 11 | - | - | ~34 | - |
| 15 | ~47 | ~24 | ~27 | ~20 |
### Series Analysis
* **Llama-68M (Blue):** Highest overall performance. It peaks early at Gamma=4 before a steady decline, maintaining a significant lead over all other models.
* **Llama-160M (Orange):** Starts as the second-fastest model. It shows a consistent decline, crossing below the 40 tokens/sec threshold around Gamma=7.
* **Vicuna-1B (Red):** Starts similarly to Llama-1B but maintains higher performance than the 1B Llama variant across all Gamma values > 2. It follows a smoother decay curve than the Llama-160M.
* **Llama-1B (Green):** Lowest overall performance. It experiences a sharp drop between Gamma 2 and Gamma 6, eventually plateauing slightly but remaining the slowest model.
## 4. Summary of Findings
* **Model Size Correlation:** There is a clear inverse correlation between model parameter count and tokens per second. The smallest model (68M) is roughly 2-3x faster than the largest models (1B) at high Gamma values.
* **Gamma Impact:** Increasing the Gamma value negatively impacts throughput across all tested models.
* **Architecture Comparison:** At the 1B parameter scale, the `Vicuna-1B` consistently outperforms the `Llama-1B` in terms of tokens per second for nearly all Gamma values shown.
* **Baseline:** The dashed line at ~45.5 tokens/sec serves as a performance benchmark; only the Llama-68M remains consistently above this line for the entire Gamma range.