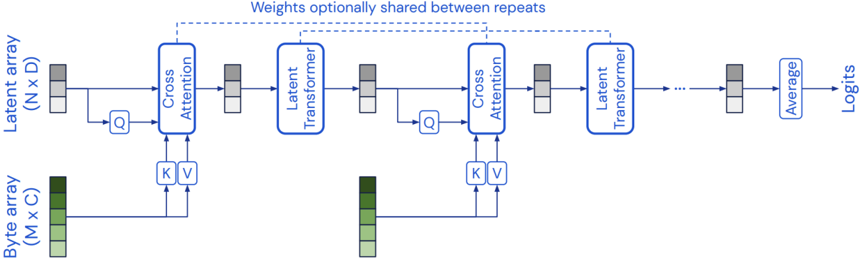
## Diagram: Latent Transformer Architecture
### Overview
The image presents a diagram of a Latent Transformer architecture. It illustrates the flow of data between different components, including byte arrays, latent arrays, cross-attention modules, and latent transformer modules. The diagram highlights the iterative nature of the process and the optional sharing of weights between repeats.
### Components/Axes
* **Latent array (N x D):** Represents a latent array with dimensions N x D. It is depicted as a stack of three gray-shaded blocks.
* **Byte array (M x C):** Represents a byte array with dimensions M x C. It is depicted as a stack of five green-shaded blocks, with the top block being the darkest and the bottom block being the lightest.
* **Cross Attention:** A module labeled "Cross Attention" in a blue rounded rectangle.
* **Latent Transformer:** A module labeled "Latent Transformer" in a blue rounded rectangle.
* **Q:** Represents a query operation, depicted as a square with "Q" inside.
* **K V:** Represents key and value operations, depicted as a square with "K V" inside.
* **Average:** A module labeled "Average" in a blue rounded rectangle.
* **Logits:** The final output of the architecture.
* **Weights optionally shared between repeats:** A text annotation above the diagram, indicating that weights can be optionally shared between repeated modules.
### Detailed Analysis
The diagram illustrates the following flow:
1. A Latent array (N x D) and a Byte array (M x C) are input to the first Cross Attention module.
2. The Latent array is transformed into a query (Q) and fed into the Cross Attention module.
3. The Byte array is transformed into keys (K) and values (V) and fed into the Cross Attention module.
4. The output of the Cross Attention module is fed into a Latent Transformer module.
5. The output of the Latent Transformer module is fed back into a query (Q) for the next Cross Attention module.
6. The process repeats with another Cross Attention and Latent Transformer module.
7. After several repetitions (indicated by "..."), the output is fed into an Average module.
8. The output of the Average module is the final Logits.
9. A dashed line above the Cross Attention and Latent Transformer modules indicates that weights can be optionally shared between repeats.
### Key Observations
* The diagram emphasizes the iterative nature of the Latent Transformer architecture.
* The use of Cross Attention modules allows the model to attend to both the Latent array and the Byte array.
* The optional sharing of weights between repeats can help to reduce the number of parameters in the model.
### Interpretation
The diagram provides a high-level overview of the Latent Transformer architecture. It demonstrates how the model processes input data through a series of Cross Attention and Latent Transformer modules to generate a final output. The architecture is designed to be flexible and efficient, allowing for the optional sharing of weights between repeats. The use of cross-attention allows the model to integrate information from both the latent and byte arrays, potentially capturing complex relationships between them. The final averaging step suggests an aggregation of information learned across multiple iterations.