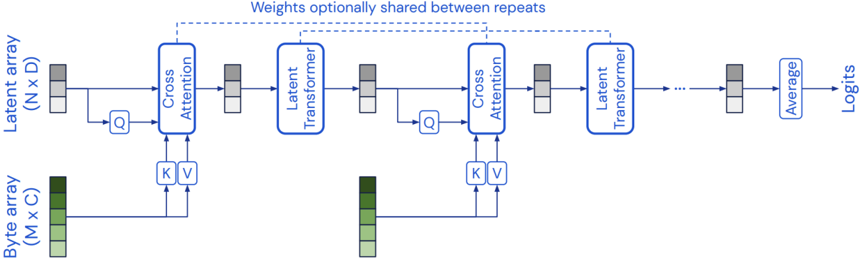
## Diagram: Neural Network Architecture with Cross-Attention and Latent Transformers
### Overview
The image displays a technical flow diagram of a neural network architecture. The model processes two distinct input arrays through a series of repeating blocks involving cross-attention and transformer layers, ultimately producing a "Logits" output. The diagram emphasizes a modular design where weights can optionally be shared between repeating blocks.
### Components/Axes
The diagram is structured as a left-to-right flowchart with the following labeled components and data flows:
1. **Input Arrays (Left Side):**
* **Latent array (N x D):** Positioned vertically on the far left. Represented by a stack of three gray rectangles. This is the primary input stream.
* **Byte array (M x C):** Positioned horizontally at the bottom left. Represented by a stack of three green rectangles. This serves as a secondary input, providing Keys (K) and Values (V) for the cross-attention mechanism.
2. **Processing Blocks (Center Flow):**
* **Cross Attention:** A blue-outlined rectangular block. It receives three inputs:
* Query (Q) from the preceding Latent array stream.
* Key (K) and Value (V) from the Byte array.
* **Latent Transformer:** A blue-outlined rectangular block that follows each Cross Attention block. It processes the output from the Cross Attention layer.
* **Average:** A blue-outlined rectangular block near the end of the chain. It aggregates the final latent representation.
* **Logits:** The final output label on the far right.
3. **Data Flow & Connections:**
* Solid blue arrows indicate the primary data flow from left to right.
* The output of one "Latent Transformer" block becomes the input latent array for the next "Cross Attention" block.
* The Byte array provides K and V inputs to *every* Cross Attention block in the sequence.
* A dashed blue line at the top connects the first and last "Latent Transformer" blocks, accompanied by the text: **"Weights optionally shared between repeats"**. This indicates a potential weight-tying mechanism across the repeating modules.
4. **Data Representations:**
* Small stacked rectangles (gray for latent, green for byte) are used throughout to represent the state of the data arrays as they pass through the network. Their consistent use helps track the transformation of the latent representation.
### Detailed Analysis
The architecture follows a clear, repeating pattern:
1. **Stage 1:** The initial `Latent array (N x D)` is split. One path provides the Query (Q) to the first **Cross Attention** block. The other path appears to bypass this block initially (indicated by a line going around it).
2. **Cross-Attention:** The first **Cross Attention** block computes attention between the latent Query (Q) and the Keys/Values (K, V) from the **Byte array (M x C)**.
3. **Transformation:** The output of the Cross Attention block is fed into the first **Latent Transformer** block.
4. **Repetition:** The output of the first Latent Transformer becomes the new latent input for the next **Cross Attention** block. This **Cross Attention -> Latent Transformer** sequence repeats multiple times (indicated by the ellipsis `...`).
5. **Weight Sharing:** The dashed line and label explicitly state that the parameters (weights) of the **Latent Transformer** blocks can be shared across all these repeating stages.
6. **Final Processing:** After the final repeating block, the latent representation passes through an **Average** operation.
7. **Output:** The averaged result is the final output, labeled **Logits**.
### Key Observations
* **Dual-Input Architecture:** The model explicitly separates a "Latent" representation from a "Byte" representation, suggesting a design where high-level latent features interact with raw or lower-level byte data.
* **Recurrent Cross-Attention:** The Byte array is used as a persistent memory or context, providing K and V to every cross-attention layer in the chain. This allows the evolving latent representation to repeatedly attend to the same byte-level information.
* **Modular and Weight-Efficient Design:** The repeating block structure and the option for weight sharing promote modularity and can significantly reduce the number of parameters if enabled.
* **Latent-Centric Processing:** The core processing pipeline (the horizontal flow) operates on the latent array, with the byte array acting as an external support input. The final "Average" and "Logits" suggest the latent representation is being used for a classification or prediction task.
### Interpretation
This diagram illustrates a neural network architecture that processes two input streams—a primary "Latent" stream and a secondary "Byte" stream—through a series of interconnected cross-attention and transformer modules.