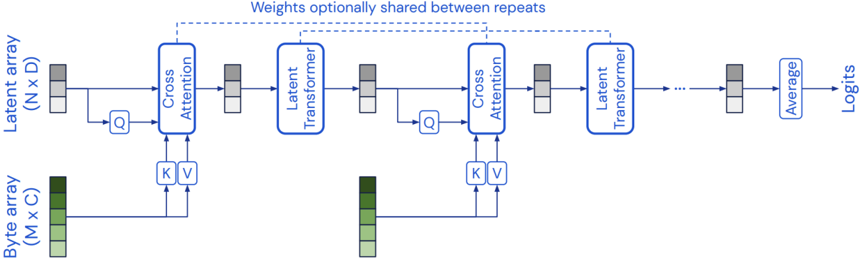
## Diagram: Latent-Byte Cross-Attention Transformer Pipeline
### Overview
The diagram illustrates a multi-stage machine learning pipeline that processes two input arrays (latent and byte) through alternating cross-attention and latent transformer blocks, culminating in logit outputs. Weights are optionally shared between repeated transformer stages.
### Components/Axes
1. **Input Arrays**:
- **Latent Array**: (N x D) dimensions, represented as gray/white blocks
- **Byte Array**: (M x C) dimensions, represented as green/light green blocks
2. **Processing Blocks**:
- **Cross Attention**: Takes queries (Q) from latent array and keys/values (K/V) from byte array
- **Latent Transformer**: Processes cross-attention outputs
3. **Output**:
- **Average**: Aggregates outputs from repeated transformer stages
- **Logits**: Final output dimension (unspecified)
### Detailed Analysis
1. **Flow Direction**:
- Latent array → Cross Attention (Q) → Cross Attention (K/V from byte array) → Latent Transformer
- Repeated pattern with optional weight sharing between transformer stages
- Final average → Logits
2. **Key Connections**:
- Dashed lines indicate optional weight sharing between transformer repeats
- Solid arrows show mandatory data flow
- Byte array feeds K/V pairs to cross-attention blocks
3. **Dimensionality**:
- Latent array: N samples × D features
- Byte array: M samples × C features
- Logits: Final output dimension (not specified)
### Key Observations
1. **Architecture Pattern**:
- Hybrid attention-transformer architecture combining latent and byte-level processing
- Cross-attention mechanism integrates two distinct data modalities
2. **Repetition Strategy**:
- Multiple transformer stages with optional parameter sharing
- Suggests hierarchical feature extraction with parameter efficiency
3. **Output Mechanism**:
- Final average operation before logits implies ensemble-like behavior
- Logits suggest classification/regression output
### Interpretation
This architecture demonstrates a sophisticated approach to multi-modal data integration:
1. **Cross-Modal Fusion**: The cross-attention blocks enable interaction between latent features (N x D) and byte-level representations (M x C), allowing the model to learn relationships between high-level abstractions and low-level data representations.
2. **Parameter Efficiency**: The optional weight sharing between transformer stages suggests a design choice to reduce computational complexity while maintaining model capacity through repeated processing.
3. **Hierarchical Processing**: The repeated transformer stages indicate a deep learning approach where features are progressively refined through multiple attention and transformation layers.
4. **Output Design**: The final average operation before logits implies that the model aggregates information across multiple processing stages before making final predictions, potentially improving robustness.
The architecture appears optimized for scenarios requiring both feature-rich latent representations and fine-grained byte-level information, with careful consideration of computational efficiency through parameter sharing.