## System Diagram: Voiceprint Analysis and Transcription
### Overview
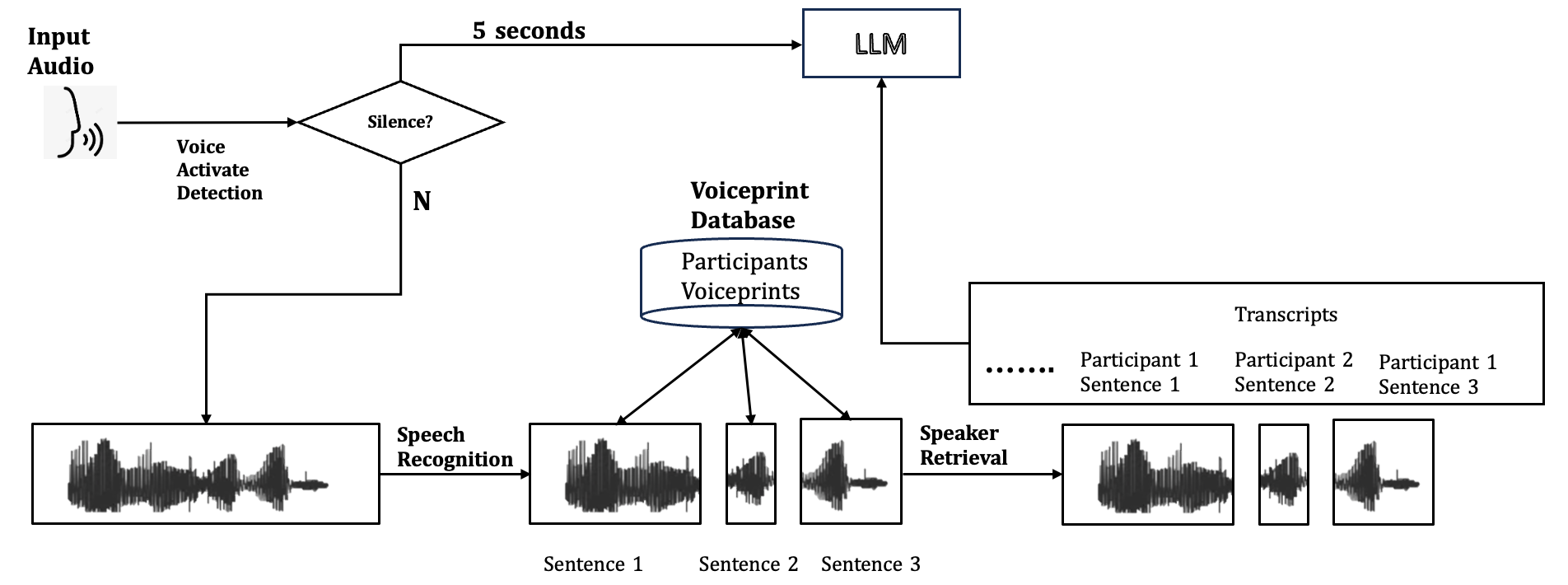
The image is a system diagram illustrating a process for voiceprint analysis and transcription using a Large Language Model (LLM). The process begins with input audio, proceeds through voice activation detection, speech recognition, speaker retrieval, and ultimately generates transcripts. A voiceprint database is used for speaker identification.
### Components/Axes
* **Input Audio:** Represents the initial audio input to the system.
* **Voice Activate Detection:** A process that determines if there is speech present in the audio.
* **Silence?:** A decision point in the process. If silence is detected for 5 seconds, the audio is sent to the LLM.
* **N:** Represents the "No" branch of the "Silence?" decision, indicating that speech is present.
* **5 seconds:** The duration of silence that triggers the LLM.
* **LLM:** Large Language Model, used for processing the audio after a period of silence.
* **Voiceprint Database:** A database containing voiceprints of participants.
* **Participants**
* **Voiceprints**
* **Speech Recognition:** Converts the audio into text.
* **Speaker Retrieval:** Identifies the speaker based on their voiceprint.
* **Transcripts:** The final output, containing the transcribed text.
* **Participant 1 Sentence 1**
* **Participant 2 Sentence 2**
* **Participant 1 Sentence 3**
* Waveform representations of speech segments labeled as:
* **Sentence 1**
* **Sentence 2**
* **Sentence 3**
### Detailed Analysis or Content Details
1. **Input Audio:** Audio enters the system.
2. **Voice Activation Detection:** The system checks for voice activity.
3. **Silence Check:** If silence is detected for 5 seconds, the audio is sent to the LLM.
4. **LLM Processing:** The LLM processes the audio.
5. **Speech Recognition:** If voice activity is detected, the audio is processed by the speech recognition module.
6. **Voiceprint Database:** The voiceprint database stores voiceprints of participants.
7. **Speaker Retrieval:** The system retrieves the speaker's identity from the voiceprint database.
8. **Transcripts:** The system generates transcripts of the audio, identifying the speaker and the content of their speech.
### Key Observations
* The system uses a combination of voice activation detection, speech recognition, and voiceprint analysis to generate transcripts.
* The LLM is used when silence is detected for a certain duration.
* The voiceprint database is crucial for speaker identification.
### Interpretation
The diagram illustrates a system designed to automatically transcribe speech and identify speakers. The system leverages voice activation detection to initiate processing, and uses a voiceprint database to identify speakers. The inclusion of an LLM suggests that the system may be capable of more advanced processing, such as summarizing or translating the audio. The system appears to be designed for scenarios where multiple speakers are involved and accurate speaker identification is important. The 5-second silence trigger for the LLM suggests a mechanism for handling pauses or breaks in speech.