TECHNICAL ASSET FINGERPRINT
ea6d0a97fc580fc00ce76dd0
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemini-2.5-flash-lite-free VERSION 1
RUNTIME: google-free/gemini-2.5-flash-lite
INTEL_VERIFIED
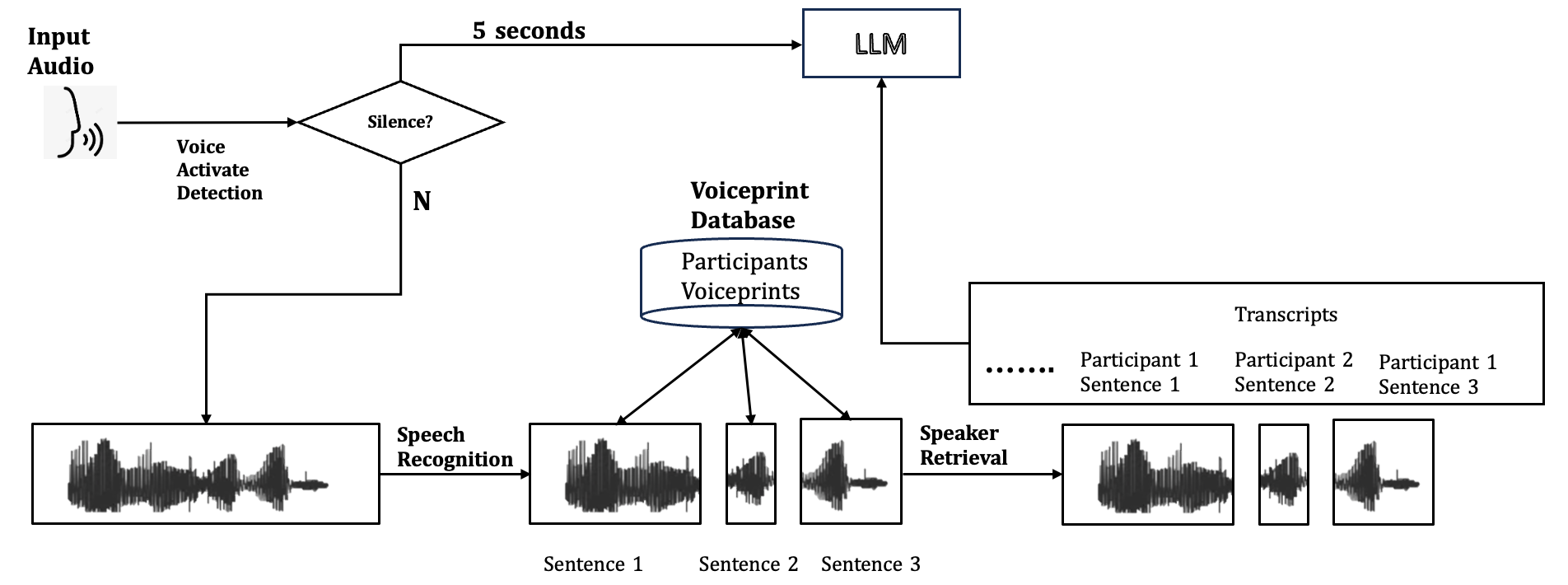
## Diagram: Audio Processing and Speaker Identification System
### Overview
This diagram illustrates a system designed to process input audio, detect silence, perform speech recognition, retrieve voiceprints from a database, and identify speakers based on their voice characteristics. The system also involves a Large Language Model (LLM) and a transcript generation component.
### Components/Axes
The diagram consists of several interconnected components represented by text labels, shapes, and arrows indicating data flow. There are no explicit axes or legends as this is a process flow diagram.
**Key Components and Labels:**
* **Input Audio:** Represented by an icon of sound waves, indicating the initial audio input.
* **Voice Activate Detection:** A process that analyzes the input audio.
* **Silence?:** A decision point (diamond shape) that checks for silence in the audio.
* **"N" (No):** An arrow labeled "N" branches from the "Silence?" decision point, indicating the path taken when silence is not detected. This path leads to "Speech Recognition."
* **"5 seconds":** An arrow labeled "5 seconds" branches from the "Silence?" decision point, indicating a time delay or a condition related to silence. This path leads to the "LLM."
* **Speech Recognition:** A process that converts spoken audio into text.
* **Waveform Visualizations:** Multiple rectangular boxes contain waveform representations of audio segments. These are labeled as:
* "Sentence 1" (under the output of Speech Recognition)
* "Sentence 1", "Sentence 2", "Sentence 3" (underneath three separate waveform visualizations originating from the Voiceprint Database)
* Three waveform visualizations are shown as outputs from "Speaker Retrieval."
* **Voiceprint Database:** A cylindrical shape labeled "Voiceprint Database" containing "Participants Voiceprints." Arrows point from this database to three individual waveform visualizations labeled "Sentence 1," "Sentence 2," and "Sentence 3."
* **Speaker Retrieval:** A process that retrieves speaker-specific voice information.
* **Transcripts:** A rectangular box labeled "Transcripts" containing entries:
* "........" (ellipsis indicating continuation)
* "Participant 1 Sentence 1"
* "Participant 2 Sentence 2"
* "Participant 1 Sentence 3"
* **LLM:** A rectangular box labeled "LLM" (Large Language Model).
### Detailed Analysis or Content Details
The diagram outlines the following process flow:
1. **Input Audio:** Raw audio is fed into the system.
2. **Voice Activate Detection:** This initial stage analyzes the audio.
3. **Silence Detection:** A decision is made on whether the audio segment contains silence.
* If **No** (audio is not silent), the audio proceeds to **Speech Recognition**.
* If **Yes** (silence is detected), a path is taken that involves a **5 seconds** delay or condition, leading to the **LLM**.
4. **Speech Recognition:** The audio segment (when not silent) is processed by speech recognition. The output of this stage is a waveform visualization labeled "Sentence 1."
5. **Voiceprint Database Interaction:**
* The "Voiceprint Database" containing "Participants Voiceprints" is accessed.
* Three distinct waveform visualizations, labeled "Sentence 1," "Sentence 2," and "Sentence 3," are shown as being retrieved from this database. These likely represent voiceprints of different sentences from different participants.
6. **Speaker Retrieval:** The retrieved voiceprints are processed by the "Speaker Retrieval" module. The output of this stage is three waveform visualizations, presumably representing the identified speaker's voice segments.
7. **LLM and Transcripts:**
* The **LLM** receives input from the "Silence?" decision point (after a 5-second delay/condition).
* The **LLM** also receives input from the "Speaker Retrieval" process.
* A "Transcripts" box is shown, containing entries like "Participant 1 Sentence 1," "Participant 2 Sentence 2," and "Participant 1 Sentence 3." This suggests that the LLM, in conjunction with speaker retrieval and potentially speech recognition outputs, generates or refines these transcripts.
### Key Observations
* The system differentiates between silent and non-silent audio segments.
* Silence detection has a direct impact on the LLM's input, suggesting a role in managing context or triggering specific LLM functions based on audio activity.
* There is a clear separation between speech recognition (converting audio to text) and speaker retrieval (identifying the speaker based on voice characteristics).
* The Voiceprint Database is central to speaker identification, providing reference voiceprints.
* The LLM appears to be a core processing unit, integrating information from silence detection and speaker retrieval to produce or enhance transcripts.
* The "Transcripts" section implies that the system aims to associate spoken content with specific participants and sentences.
### Interpretation
This diagram depicts a sophisticated audio processing pipeline that combines speech recognition, speaker identification, and natural language processing (via the LLM). The system's primary goal seems to be the accurate transcription and speaker attribution of audio content.
The "Silence?" decision point and the associated "5 seconds" path to the LLM suggest that the system might be designed to handle pauses or periods of inactivity in a specific way. This could be for buffering, context management, or to avoid processing irrelevant audio segments. The direct connection from "Silence?" to LLM implies that the LLM might be informed about the presence or absence of speech, which could influence its subsequent processing or output.
The "Voiceprint Database" and "Speaker Retrieval" components are crucial for multi-speaker scenarios. By comparing incoming audio segments against stored voiceprints, the system can identify who is speaking. This is a common requirement in applications like call center analytics, meeting transcription, or voice-activated assistants that need to distinguish between users.
The "Transcripts" section, populated with participant and sentence information, indicates that the final output is not just raw text but also includes metadata about the speaker and the content they uttered. The LLM's role in this final stage is likely to refine the accuracy of the transcripts, potentially correcting errors from the speech recognition module, or even inferring context and meaning based on the identified speaker and the transcribed text. The ellipsis in the "Transcripts" box suggests that the system can handle a variable number of participants and sentences.
In essence, the diagram illustrates a system that aims to provide a structured and attributed textual representation of spoken audio, leveraging both acoustic and linguistic processing. The integration of a voiceprint database and an LLM suggests a focus on accuracy, speaker verification, and potentially advanced natural language understanding.
DECODING INTELLIGENCE...