\n
## Diagram: Voice Processing Pipeline
### Overview
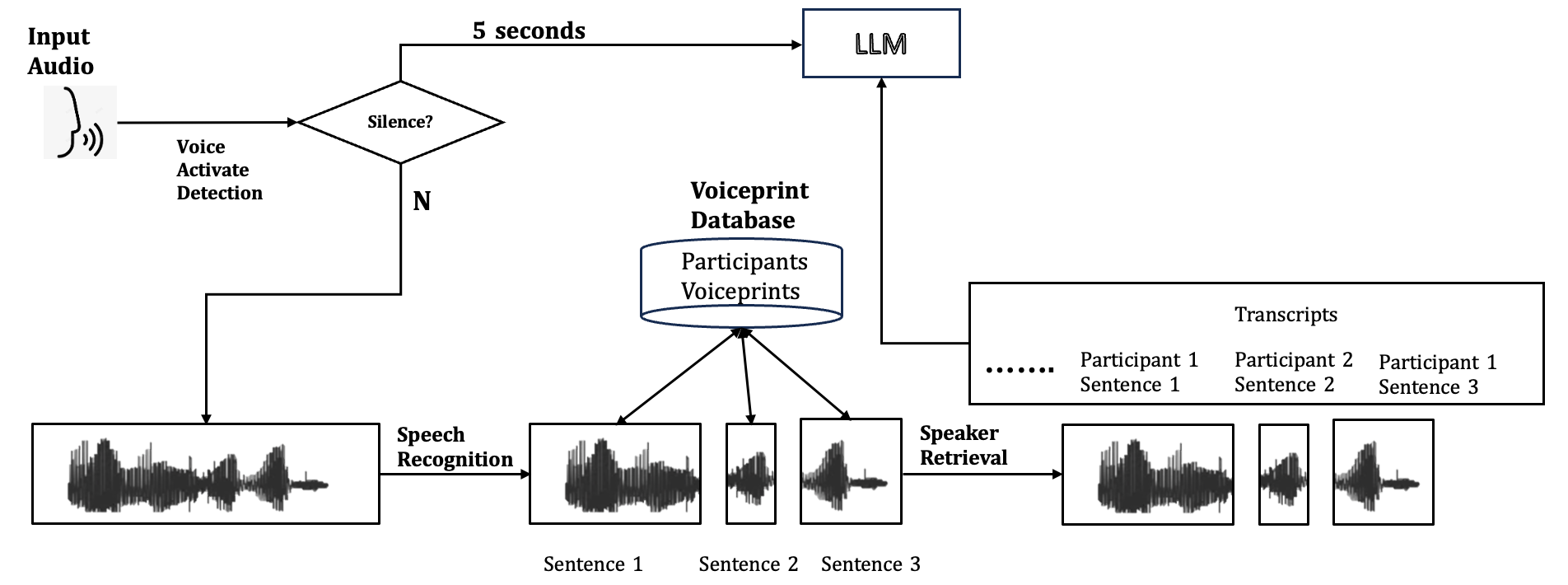
This diagram illustrates a voice processing pipeline, starting with audio input and culminating in transcripts generated by a Large Language Model (LLM). The pipeline includes stages for voice activation detection, speech recognition, speaker retrieval, and integration with a voiceprint database.
### Components/Axes
The diagram consists of the following components:
* **Input Audio:** Represented by a microphone icon.
* **Voice Activate Detection:** A decision block checking for silence. "N" indicates a "No" response (voice detected).
* **Speech Recognition:** Converts audio waveforms into text ("Sentence 1", "Sentence 2", "Sentence 3").
* **Voiceprint Database:** Contains "Participants Voiceprints".
* **Speaker Retrieval:** Identifies the speaker from the voiceprint database.
* **LLM:** A Large Language Model, the final processing stage.
* **Transcripts:** Output text associated with each participant ("Participant 1 Sentence 1", "Participant 2 Sentence 2", "Participant 1 Sentence 3").
* **Time Delay:** A horizontal arrow labeled "5 seconds" connecting the Voice Activate Detection to the LLM.
* **Waveforms:** Represent audio signals at various stages.
### Detailed Analysis or Content Details
The pipeline operates as follows:
1. **Input Audio** is received.
2. **Voice Activate Detection** checks for silence. If no silence is detected ("N"), the process continues.
3. The audio is passed to **Speech Recognition**, which converts it into text. Three example sentences are shown: "Sentence 1", "Sentence 2", and "Sentence 3".
4. The audio waveforms are also sent to **Speaker Retrieval**.
5. **Speaker Retrieval** accesses the **Voiceprint Database** to identify the speaker.
6. The identified speaker and the corresponding transcripts are then fed into the **LLM**.
7. The **LLM** generates final transcripts, labeled with the participant and sentence number: "Participant 1 Sentence 1", "Participant 2 Sentence 2", "Participant 1 Sentence 3".
8. There is a 5-second delay between voice activation and input to the LLM.
### Key Observations
* The diagram highlights a closed-loop system where audio is processed through multiple stages to achieve accurate transcription and speaker identification.
* The inclusion of a voice activation detection stage suggests a focus on minimizing processing of silent periods.
* The 5-second delay indicates a potential latency in the system.
* The diagram shows a simplified representation of the process, likely omitting details such as error handling or noise reduction.
### Interpretation
This diagram depicts a typical architecture for a voice-based system, such as a voice assistant or a transcription service. The pipeline demonstrates the integration of several key technologies: voice activity detection, automatic speech recognition (ASR), speaker diarization (through voiceprint matching), and natural language processing (NLP) via the LLM. The 5-second delay could be due to the time required for speech recognition, speaker retrieval, and LLM processing. The system aims to convert spoken audio into structured text data, associating each sentence with the correct speaker. The use of a voiceprint database suggests a focus on identifying known speakers, potentially for security or personalization purposes. The diagram suggests a system designed for multi-participant conversations, as evidenced by the multiple transcripts associated with different participants.