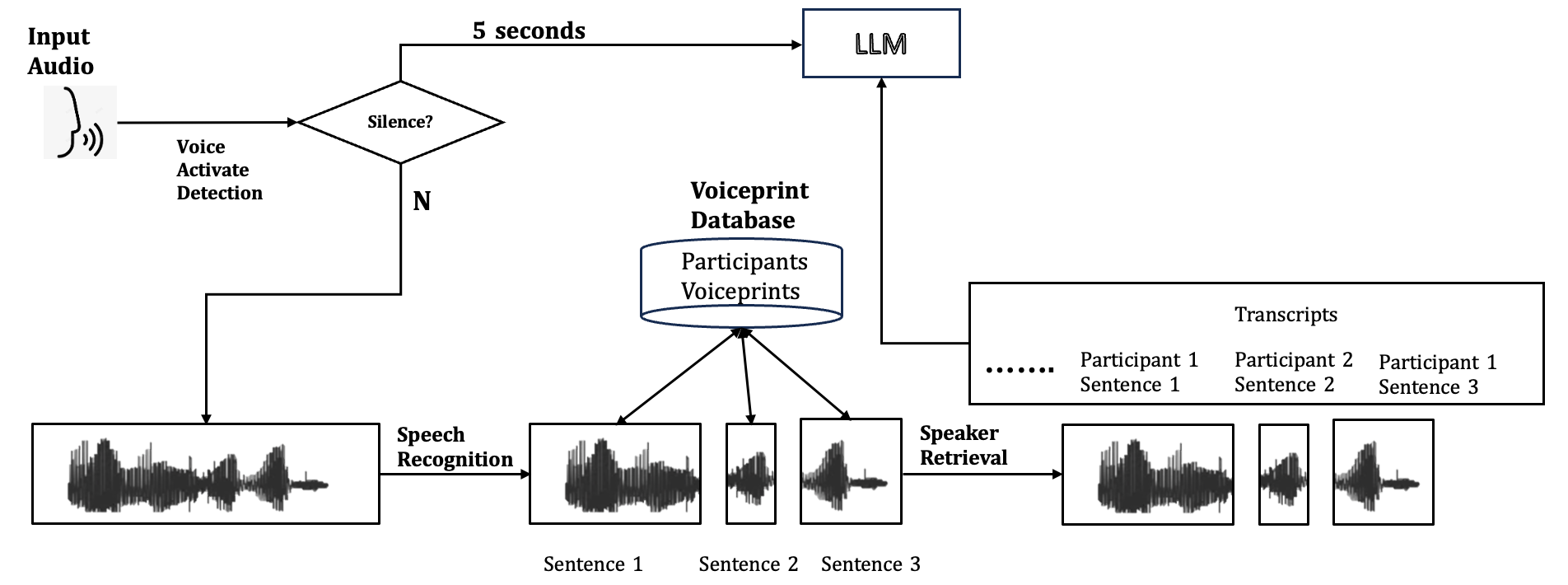
## Flowchart: Voice-Activated Speaker Authentication System
### Overview
This flowchart illustrates a voice-activated system that processes audio input, detects speech, authenticates speakers via voiceprint matching, and retrieves transcribed sentences. The system uses a 5-second silence detection threshold and integrates a large language model (LLM) for processing.
### Components/Axes
1. **Input Audio**: Starting point for audio input.
2. **Voice Activate Detection**: Determines if audio input meets activation criteria.
3. **Silence? (5 seconds)**: Decision node checking for 5 seconds of silence.
4. **LLM (Large Language Model)**: Processes non-silent audio input.
5. **Voiceprint Database**: Central repository containing:
- Participants
- Voiceprints
- Transcripts (Participant 1 Sentence 1, Participant 2 Sentence 2, etc.)
6. **Speech Recognition**: Converts audio to text for Sentence 1, 2, and 3.
7. **Speaker Retrieval**: Matches voiceprints to specific sentences.
### Detailed Analysis
- **Flow Direction**:
- Input Audio → Voice Activate Detection → [Silence? (5s)] →
- If silence: End of process
- If not silence: Audio → LLM → Voiceprint Database
- **Voiceprint Database**:
- Stores participant voiceprints and associated transcripts
- Acts as reference for speaker identification
- **Speech Recognition**:
- Generates text transcripts for Sentence 1, 2, and 3
- Outputs waveform visualizations for each sentence
- **Speaker Retrieval**:
- Cross-references voiceprints with audio input
- Maps sentences to specific participants
### Key Observations
1. **Temporal Threshold**: 5-second silence detection creates a clear activation boundary
2. **Database Structure**: Centralized storage of both voiceprints and transcripts enables multi-modal authentication
3. **Sentence Mapping**: Each sentence (1-3) has distinct waveform visualizations and participant associations
4. **LLM Integration**: Positioned after initial audio processing suggests complex language understanding capabilities
### Interpretation
This system demonstrates a multi-stage authentication process where:
1. Audio input must first meet activation criteria (non-silence for 5+ seconds)
2. Processed audio is analyzed by LLM for content understanding
3. Voiceprint database serves dual purpose:
- Speaker identification via biometric matching
- Transcript retrieval for content verification
4. The parallel paths for Speech Recognition and Speaker Retrieval suggest simultaneous processing of content and identity
The architecture implies a security-conscious design where both speaker identity and content accuracy are verified through biometric and linguistic analysis. The 5-second silence threshold likely prevents accidental activation while maintaining responsiveness.