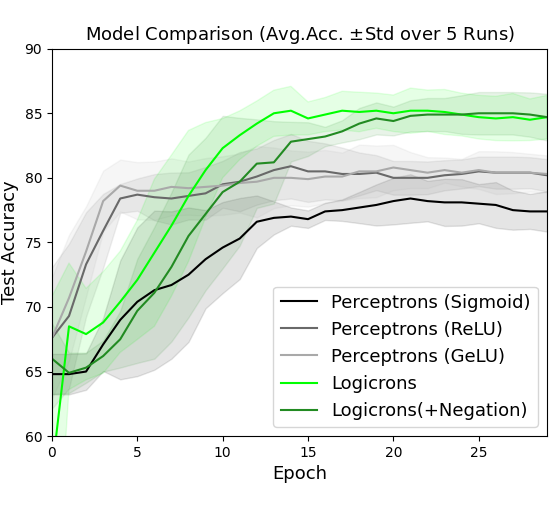
## Line Chart: Model Comparison (Avg. Acc. ± Std over 5 Runs)
### Overview
The chart compares the test accuracy of four neural network models over 25 training epochs. Each model's performance is represented by a line with a shaded confidence interval (± standard deviation). The y-axis shows test accuracy (%), and the x-axis shows training epochs.
### Components/Axes
- **X-axis (Epoch)**: Ranges from 0 to 25 in increments of 5.
- **Y-axis (Test Accuracy)**: Ranges from 60% to 90% in increments of 5%.
- **Legend**: Located at bottom-right, with four entries:
- **Black line**: Perceptrons (Sigmoid)
- **Gray line**: Perceptrons (ReLU)
- **Light gray line**: Perceptrons (GeLU)
- **Green line**: Logicrons (+Negation)
### Detailed Analysis
1. **Logicrons (+Negation)** (Green):
- Starts at 60% accuracy at epoch 0.
- Sharp upward trend, reaching 78% by epoch 10.
- Plateaus at ~85% from epoch 15 onward.
- Confidence interval widens initially (epochs 0-5) but stabilizes after epoch 10.
2. **Perceptrons (Sigmoid)** (Black):
- Begins at 65% accuracy at epoch 0.
- Gradual increase to 78% by epoch 15.
- Slows to a plateau at ~78% by epoch 20.
- Confidence interval remains narrow throughout.
3. **Perceptrons (ReLU)** (Gray):
- Starts at 70% accuracy at epoch 0.
- Steady rise to 80% by epoch 15.
- Flattens at ~80% by epoch 20.
- Confidence interval shows moderate variability.
4. **Perceptrons (GeLU)** (Light Gray):
- Begins at 68% accuracy at epoch 0.
- Increases to 79% by epoch 15.
- Stabilizes at ~79% by epoch 20.
- Confidence interval shows slight widening after epoch 10.
### Key Observations
- **Logicrons (+Negation)** outperform all Perceptron variants after epoch 10, achieving the highest final accuracy (~85%).
- **Perceptrons (Sigmoid)** starts strongest but underperforms by epoch 20.
- **ReLU** and **GeLU** variants show similar trajectories, with ReLU slightly ahead.
- All models exhibit diminishing returns after epoch 15-20.
### Interpretation
The data demonstrates that **Logicrons with negation** achieve superior long-term performance despite slower initial progress. Perceptron variants with ReLU/GeLU activation functions show moderate performance, while Sigmoid activation leads to early gains but poor scalability. The shaded confidence intervals highlight that Logicrons exhibit higher variability in early training, suggesting sensitivity to hyperparameters or initialization. The plateauing trends across all models indicate potential convergence limits, emphasizing the importance of architectural choices over mere activation function selection.