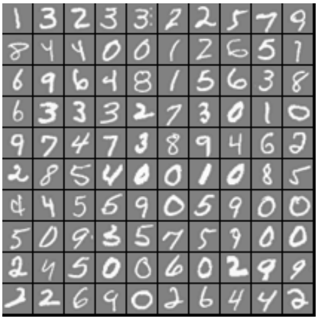
## Image Grid: Handwritten Digits Sample (MNIST Dataset Style)
### Overview
The image displays a 10x10 grid containing 100 individual grayscale images of handwritten Arabic numerals (0 through 9). The digits are rendered in white/light gray against a uniform dark gray background. The image is highly characteristic of a sample batch from the MNIST (Modified National Institute of Standards and Technology) database, which is a standard benchmark dataset used in machine learning and computer vision for training image processing systems.
### Components/Axes
* **Axes/Scales:** There are no X or Y axes, scales, or tick marks present.
* **Legends/Labels:** There are no textual labels, titles, or legends.
* **Grid Structure:** The image is divided by thin black lines into a 10-row by 10-column matrix, yielding 100 distinct cells. Each cell acts as a bounding box for a single digit.
### Content Details
Below is the precise transcription of the handwritten digits, mapped spatially to their exact row and column positions within the grid.
*Note: Due to the nature of human handwriting, a few digits exhibit structural ambiguity (e.g., Row 7, Column 1 resembles a '4' with an extra vertical stroke; Row 1, Column 5 is a '3' with artifact dots). The transcription represents the most highly probable intended digit.*
| Row \ Col | C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 | C10 |
| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
| **R1** | 1 | 3 | 2 | 3 | 3 | 2 | 2 | 5 | 7 | 9 |
| **R2** | 8 | 4 | 4 | 0 | 0 | 1 | 2 | 6 | 5 | 1 |
| **R3** | 6 | 9 | 6 | 4 | 8 | 1 | 5 | 6 | 3 | 8 |
| **R4** | 6 | 3 | 3 | 3 | 2 | 7 | 3 | 0 | 1 | 0 |
| **R5** | 9 | 7 | 4 | 7 | 3 | 8 | 9 | 4 | 6 | 2 |
| **R6** | 2 | 8 | 5 | 4 | 0 | 0 | 1 | 0 | 8 | 5 |
| **R7** | 4 | 4 | 5 | 6 | 9 | 0 | 5 | 9 | 0 | 0 |
| **R8** | 5 | 0 | 9 | 3 | 5 | 7 | 5 | 9 | 0 | 0 |
| **R9** | 2 | 4 | 5 | 0 | 0 | 6 | 0 | 2 | 9 | 9 |
| **R10** | 2 | 2 | 6 | 9 | 0 | 2 | 6 | 4 | 4 | 2 |
### Key Observations
* **High Variance in Stroke:** There is significant variation in stroke thickness, slant, and overall morphology for the same digits.
* *Example:* The '1's range from perfectly vertical lines (R1, C1) to heavily slanted lines (R2, C10).
* *Example:* The '2's feature both looped bases (R1, C3) and sharp, angled bases (R10, C1).
* *Example:* The '7's include both standard strokes (R1, C9) and crossed strokes (R5, C2).
* **Artifacts/Noise:** Row 1, Column 5 contains a '3' with three distinct white dots (noise) to the right of the digit within its cell.
* **Distribution:** The digits appear to be randomly shuffled rather than ordered sequentially or grouped by class.
* **Centering:** All digits appear to be roughly size-normalized and centered within their respective grid cells.
### Interpretation
* **Purpose of the Data:** This image does not represent a chart of quantitative trends; rather, it is a visualization of raw data used for Optical Character Recognition (OCR). It demonstrates the input layer for a machine learning model (likely a Convolutional Neural Network).
* **The Challenge of Generalization:** The primary takeaway from this visual data is the inherent complexity of human handwriting. A successful algorithm must learn the underlying topological features of a "3" or a "5" while ignoring the vast superficial differences in slant, thickness, and minor artifacts (like the dots in R1, C5).
* **Preprocessing Indicators:** The uniform gray background (rather than pure black) suggests that the image data may have undergone preprocessing, such as mean subtraction or normalization, which is a common step before feeding image matrices into neural networks to stabilize the learning process. The strict bounding boxes confirm the data has been segmented and scaled to a uniform pixel dimension (traditionally 28x28 pixels per cell for MNIST).