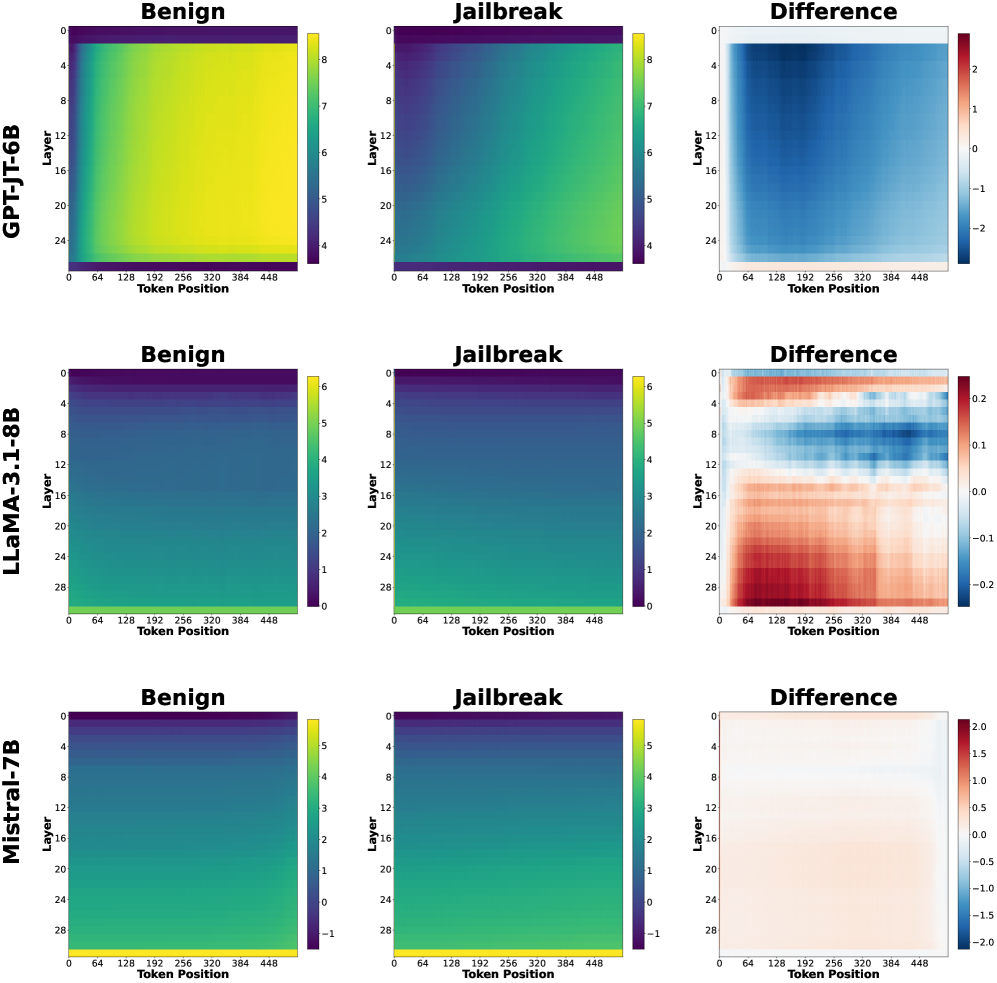
## Heatmap: Benign vs. Jailbreak Token Embeddings
### Overview
The image presents a series of heatmaps comparing the token embeddings of three language models (GPT-JT-6B, LLaMA-3.1-8B, and Mistral-7B) under two conditions: "Benign" and "Jailbreak". The heatmaps visualize the activation levels across different layers and token positions. A third heatmap shows the "Difference" between the Benign and Jailbreak conditions.
### Components/Axes
* **Rows:** Each row represents a different language model: GPT-JT-6B (top), LLaMA-3.1-8B (middle), and Mistral-7B (bottom).
* **Columns:** Each set of three columns represents a condition: "Benign", "Jailbreak", and "Difference".
* **Y-axis (Layer):** The y-axis represents the layer number of the language model. The layer numbers increase from top to bottom.
* GPT-JT-6B: Layers range from 0 to 24.
* LLaMA-3.1-8B: Layers range from 0 to 28.
* Mistral-7B: Layers range from 0 to 28.
* **X-axis (Token Position):** The x-axis represents the token position, ranging from 0 to 448.
* **Color Scale (Benign & Jailbreak):** The color scale represents the activation level, with warmer colors (yellow) indicating higher activation and cooler colors (purple/dark blue) indicating lower activation.
* GPT-JT-6B: Ranges from approximately 4 to 8.
* LLaMA-3.1-8B: Ranges from approximately 0 to 6.
* Mistral-7B: Ranges from approximately -1 to 5.
* **Color Scale (Difference):** The color scale represents the difference in activation levels between the "Benign" and "Jailbreak" conditions. Red indicates a positive difference (higher activation in "Benign"), and blue indicates a negative difference (higher activation in "Jailbreak").
* GPT-JT-6B: Ranges from approximately -2 to 2.
* LLaMA-3.1-8B: Ranges from approximately -0.2 to 0.2.
* Mistral-7B: Ranges from approximately -2 to 2.
### Detailed Analysis
#### GPT-JT-6B
* **Benign:** The heatmap shows relatively high activation across all layers and token positions, with a slight decrease in activation towards the bottom layers. The activation is generally uniform.
* **Jailbreak:** The heatmap shows a similar pattern to the "Benign" condition, but with slightly lower overall activation.
* **Difference:** The heatmap shows a clear negative difference (blue) in the upper layers (approximately 0-8), indicating higher activation in the "Jailbreak" condition for these layers. The lower layers show a slight positive difference (red), indicating higher activation in the "Benign" condition.
#### LLaMA-3.1-8B
* **Benign:** The heatmap shows lower activation in the upper layers, gradually increasing towards the bottom layers.
* **Jailbreak:** The heatmap shows a similar pattern to the "Benign" condition.
* **Difference:** The heatmap shows a more complex pattern. The upper layers (approximately 0-8) show a negative difference (blue), while the middle layers (approximately 8-20) show a positive difference (red). The bottom layers show a mix of positive and negative differences.
#### Mistral-7B
* **Benign:** The heatmap shows a similar pattern to LLaMA-3.1-8B, with lower activation in the upper layers and increasing activation towards the bottom layers.
* **Jailbreak:** The heatmap shows a similar pattern to the "Benign" condition.
* **Difference:** The heatmap shows a relatively small difference between the "Benign" and "Jailbreak" conditions. The upper layers show a slight negative difference (blue), while the lower layers show a slight positive difference (red).
### Key Observations
* The "Difference" heatmaps highlight the layers and token positions where the "Benign" and "Jailbreak" conditions diverge the most.
* GPT-JT-6B shows the most pronounced difference in the upper layers, with higher activation in the "Jailbreak" condition.
* LLaMA-3.1-8B shows a more complex difference pattern, with both positive and negative differences across different layers.
* Mistral-7B shows the smallest difference between the two conditions.
* The token position does not appear to have a strong influence on the activation levels, as the heatmaps are relatively uniform along the x-axis.
### Interpretation
The heatmaps provide a visual representation of how different language models respond to "Benign" and "Jailbreak" prompts. The "Difference" heatmaps are particularly useful for identifying the layers that are most affected by the "Jailbreak" condition.
The data suggests that GPT-JT-6B is more susceptible to "Jailbreak" attacks, as evidenced by the significant difference in activation levels in the upper layers. LLaMA-3.1-8B shows a more nuanced response, with different layers exhibiting different behaviors. Mistral-7B appears to be the most robust against "Jailbreak" attacks, as the difference between the two conditions is minimal.
These findings could be used to develop more effective defense mechanisms against "Jailbreak" attacks by focusing on the layers that are most vulnerable. Further research is needed to understand the underlying mechanisms that cause these differences in behavior.