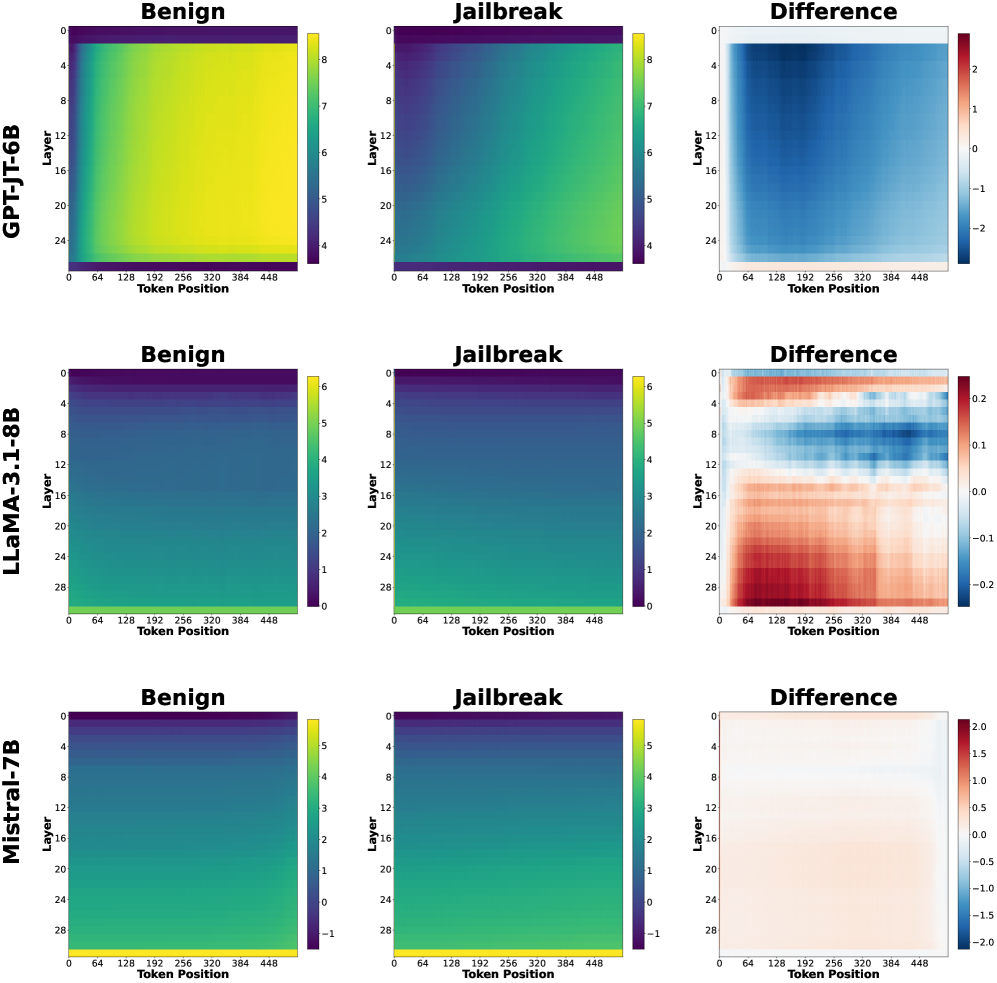
## Heatmaps: Activation Analysis of Language Models - Benign vs. Jailbreak
### Overview
The image presents a 3x3 grid of heatmaps, comparing the activation patterns of three different language models (GPT-JT-6B, LLaMA-3-1.8B, and Mistral-7B) under benign and jailbreak prompts. Each model has three heatmaps: one for benign prompts, one for jailbreak prompts, and one showing the difference between the two. The heatmaps visualize activation levels across layers (y-axis) and token positions (x-axis).
### Components/Axes
* **Models:** GPT-JT-6B, LLaMA-3-1.8B, Mistral-7B (arranged vertically)
* **Prompts:** Benign, Jailbreak, Difference (arranged horizontally)
* **X-axis:** Token Position (ranging from approximately 0 to 448, with markers at 64, 128, 192, 256, 320, 384, and 448)
* **Y-axis:** Layer (ranging from approximately 0 to 24, with markers at 4, 8, 12, 16, 20, and 24)
* **Color Scales:** Each heatmap has a distinct color scale representing activation levels.
* GPT-JT-6B Difference: Ranges from -2 (blue) to 2 (red).
* LLaMA-3-1.8B Difference: Ranges from -0.2 (blue) to 0.2 (red).
* Mistral-7B Difference: Ranges from -1.5 (blue) to 1.5 (red).
* Benign and Jailbreak heatmaps use a similar color scheme, but the scales are not explicitly labeled.
### Detailed Analysis or Content Details
**GPT-JT-6B:**
* **Benign:** The heatmap is predominantly yellow/green, indicating moderate activation across all layers and token positions. There's a slight gradient, with higher activation in the middle layers (around layer 12-16).
* **Jailbreak:** Similar to the benign heatmap, it's mostly yellow/green. There's a slightly more pronounced gradient, with a potential increase in activation in the middle layers.
* **Difference:** The heatmap shows a clear pattern. The top half (layers 0-12) is predominantly blue (negative difference), indicating lower activation during jailbreak compared to benign prompts. The bottom half (layers 12-24) is predominantly red (positive difference), indicating higher activation during jailbreak. The strongest differences are around token positions 192-320.
**LLaMA-3-1.8B:**
* **Benign:** The heatmap is almost entirely yellow, indicating consistent moderate activation across all layers and token positions.
* **Jailbreak:** Similar to the benign heatmap, it's mostly yellow. There's a very subtle gradient.
* **Difference:** The heatmap shows very small differences. Most of the heatmap is white/light yellow (close to zero difference). There are some very faint blue and red areas, indicating minor activation differences.
**Mistral-7B:**
* **Benign:** The heatmap is predominantly yellow/green, with a gradient showing higher activation in the middle layers (around layer 12-16).
* **Jailbreak:** Similar to the benign heatmap, it's mostly yellow/green. There's a slightly more pronounced gradient.
* **Difference:** The heatmap shows a pattern similar to GPT-JT-6B, but more pronounced. The top half (layers 0-12) is predominantly blue (negative difference), and the bottom half (layers 12-24) is predominantly red (positive difference). The strongest differences are around token positions 192-320.
### Key Observations
* GPT-JT-6B and Mistral-7B exhibit a clear shift in activation patterns between benign and jailbreak prompts, with different layers responding differently.
* LLaMA-3-1.8B shows minimal activation differences between benign and jailbreak prompts.
* The difference heatmaps for GPT-JT-6B and Mistral-7B suggest that the lower layers are more suppressed during jailbreak, while the higher layers are more activated.
* The most significant differences in activation appear to occur around token positions 192-320 for GPT-JT-6B and Mistral-7B.
### Interpretation
The heatmaps suggest that GPT-JT-6B and Mistral-7B employ different activation strategies when processing benign versus jailbreak prompts. The layer-specific activation differences indicate that these models might be utilizing different parts of their neural networks to handle potentially harmful requests. The suppression of lower layers and activation of higher layers during jailbreak could be a mechanism for generating responses that bypass safety constraints.
LLaMA-3-1.8B's minimal activation differences suggest that it might be less sensitive to the type of prompt or that its activation patterns are more consistent regardless of the input. This could indicate a different internal representation of language or a more robust safety mechanism.
The concentration of differences around token positions 192-320 might correspond to the part of the prompt where the jailbreak attempt is most evident. This could be a region where the model detects a potentially harmful request and adjusts its activation accordingly.
These findings highlight the importance of analyzing internal activations to understand how language models respond to different types of prompts and to identify potential vulnerabilities. The differences in activation patterns across models suggest that different architectures and training procedures can lead to varying levels of sensitivity to jailbreak attempts.