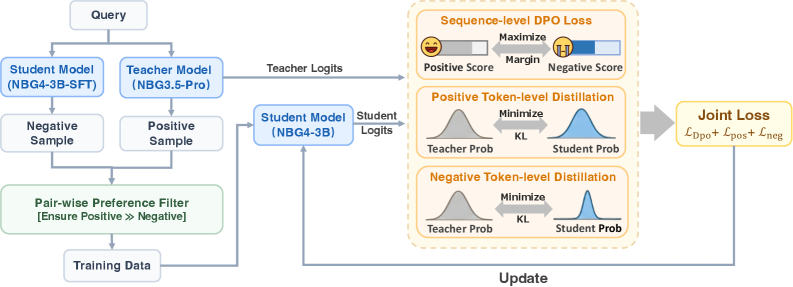
## Diagram: Machine Learning Model Training Pipeline with Knowledge Distillation
### Overview
This diagram illustrates a technical pipeline for training a student machine learning model (NBG4-3B) using knowledge distillation from a teacher model (NBG3.5-Pro). The process involves query processing, sample selection, preference filtering, logit generation, and multi-stage loss optimization to update the student model.
### Components/Axes
1. **Input/Output Flow**:
- **Query**: Top-left entry point.
- **Training Data**: Bottom-left output after filtering.
- **Update**: Bottom-right output after loss optimization.
2. **Key Components**:
- **Models**:
- Student Model (NBG4-3B-SFT)
- Teacher Model (NBG3.5-Pro)
- Student Model (NBG4-3B)
- **Samples**:
- Negative Sample
- Positive Sample
- **Filters**:
- Pair-wise Preference Filter (green box)
- **Logits**:
- Teacher Logits
- Student Logits
- **Loss Functions**:
- Sequence-level DPO Loss
- Positive Token-level Distillation
- Negative Token-level Distillation
- Joint Loss (L_DPO + L_pos + L_neg)
3. **Visual Elements**:
- Arrows indicate data flow direction.
- Color-coded blocks (blue for models, green for filters, orange for loss functions).
- Distributions (bell curves) for token-level distillation.
- Emoji-based scoring (😊 for positive, 😞 for negative).
### Detailed Analysis
1. **Query Processing**:
- Queries split into **Negative Sample** (left) and **Positive Sample** (right) for both student and teacher models.
2. **Pair-wise Preference Filter**:
- Ensures **Positive >> Negative** samples are prioritized for training data.
3. **Logit Generation**:
- Teacher Model generates **Teacher Logits** from positive samples.
- Student Model (NBG4-3B) generates **Student Logits** from positive samples.
4. **Loss Optimization**:
- **Sequence-level DPO Loss**: Maximizes positive scores (😊) and minimizes negative scores (😞) with a margin.
- **Token-level Distillation**:
- Positive: Minimizes KL divergence between teacher and student probabilities.
- Negative: Same minimization for negative samples.
- **Joint Loss**: Combines DPO, positive, and negative losses for model updates.
### Key Observations
- The pipeline emphasizes **positive sample prioritization** via the preference filter.
- **KL divergence** is used to align student and teacher token-level probabilities.
- **DPO Loss** introduces a margin-based scoring system for sequence-level optimization.
- The **joint loss** integrates multiple objectives for holistic model updates.
### Interpretation
This diagram represents a **knowledge distillation framework** where the student model learns from the teacher model's outputs while incorporating preference-based alignment (DPO) and token-level probability matching. The use of both sequence-level (DPO) and token-level (KL) losses suggests a multi-granularity approach to model improvement. The green "Pair-wise Preference Filter" acts as a quality control mechanism, ensuring the student model focuses on high-quality positive examples. The emoji-based scoring system visually reinforces the optimization goals, making the pipeline's objectives intuitive despite its technical complexity.