\n
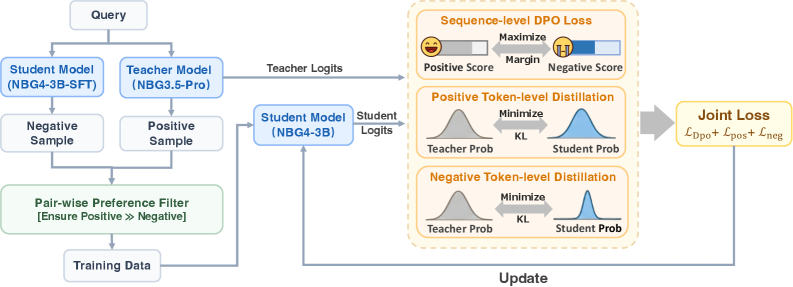
## System Architecture Diagram: Student Model Training via Teacher Distillation and DPO
### Overview
This image is a technical flowchart illustrating a machine learning training pipeline. It depicts a process where a smaller "Student Model" (NBG4-3B) is trained using outputs from a larger "Teacher Model" (NBG3.5-Pro) and preference data. The system combines Sequence-level Direct Preference Optimization (DPO) loss with token-level distillation losses to update the student model.
### Components/Axes
The diagram is organized into three main regions from left to right: **Data Preparation**, **Model Forward Pass**, and **Loss Calculation & Update**.
**1. Data Preparation (Left Region):**
* **Input:** A "Query" box at the top-left.
* **Models:** Two parallel boxes below the query:
* "Student Model (NBG4-3B-SFT)"
* "Teacher Model (NBG3.5-Pro)"
* **Samples:** Each model generates a sample:
* Student Model → "Negative Sample"
* Teacher Model → "Positive Sample"
* **Filtering:** Both samples feed into a "Pair-wise Preference Filter" box with the annotation: "[Ensure Positive >> Negative]".
* **Output:** The filter outputs to a "Training Data" box.
**2. Model Forward Pass (Center Region):**
* The "Training Data" and the original "Query" are used as input to the core "Student Model (NBG4-3B)".
* This model produces two outputs:
* An arrow labeled "Student Logits" points to the right.
* An arrow labeled "Teacher Logits" originates from the "Teacher Model (NBG3.5-Pro)" in the left region and points to the right, bypassing the student model.
**3. Loss Calculation & Update (Right Region):**
This region is enclosed in a dashed yellow box and contains three parallel loss computation modules, all receiving "Teacher Logits" and "Student Logits".
* **Top Module: "Sequence-level DPO Loss"**
* Contains two score bars: "Positive Score" (orange) and "Negative Score" (blue).
* An arrow between them is labeled "Maximize Margin".
* **Middle Module: "Positive Token-level Distillation"**
* Shows two probability distribution curves: "Teacher Prob" (gray) and "Student Prob" (blue).
* An arrow between them is labeled "Minimize KL" (Kullback-Leibler divergence).
* **Bottom Module: "Negative Token-level Distillation"**
* Identical structure to the middle module: "Teacher Prob" (gray) and "Student Prob" (blue) curves with a "Minimize KL" arrow.
* **Final Output:** The outputs of all three modules converge into a final box labeled "Joint Loss" with the formula: `L_Dpo + L_pos + L_neg`.
* **Update Loop:** An arrow labeled "Update" flows from the "Joint Loss" box back to the "Student Model (NBG4-3B)" in the center, completing the training loop.
### Detailed Analysis
The diagram specifies a multi-objective training strategy:
1. **Preference Learning:** The "Pair-wise Preference Filter" ensures the training data consists of query-response pairs where the teacher's response (positive) is explicitly preferred over the student's initial response (negative).
2. **Hybrid Loss Function:** The student model is updated to minimize a composite loss:
* **`L_Dpo` (Sequence-level):** Optimizes the model to assign a higher score (margin) to the preferred (positive) sequence over the dispreferred (negative) one.
* **`L_pos` (Token-level):** Uses knowledge distillation (minimizing KL divergence) to make the student's token-level probability distribution for the *positive* sample match the teacher's distribution.
* **`L_neg` (Token-level):** Similarly distills knowledge for the *negative* sample, aligning the student's distribution with the teacher's on the less preferred output.
### Key Observations
* **Model Naming Convention:** The student model is referred to as "NBG4-3B-SFT" (likely Supervised Fine-Tuned) during data generation and as "NBG4-3B" during the core training loop, suggesting the SFT version is a starting point.
* **Asymmetric Role:** The teacher model (NBG3.5-Pro) is only used to generate the positive sample and provide logits for distillation; it is not updated.
* **Dual Distillation:** The system performs distillation on both positive and negative samples, which is a nuanced approach to transfer the teacher's behavior comprehensively.
* **Spatial Flow:** The layout clearly separates the one-time data preparation (left) from the iterative training loop (center and right).
### Interpretation
This diagram represents a sophisticated **knowledge distillation and alignment pipeline** for training a compact language model (3B parameters). The core innovation is the **joint optimization** of three distinct learning signals:
1. **Preference Alignment (DPO):** Teaches the model *what* is better (positive vs. negative responses).
2. **Behavioral Cloning (Distillation):** Teaches the model *how* the teacher thinks, by mimicking its internal probability distributions at the token level for both good and bad responses.
The "Pair-wise Preference Filter" is a critical component, acting as a gatekeeper to ensure the training signal is clean and the positive sample is indeed superior. The overall goal is to produce a student model that not only prefers the teacher's outputs but also internalizes the teacher's reasoning patterns, leading to a more capable and aligned smaller model. The use of "NBG" in model names suggests this may be part of a specific model family or project.