TECHNICAL ASSET FINGERPRINT
ec0c71cc189dfe261bd7a751
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
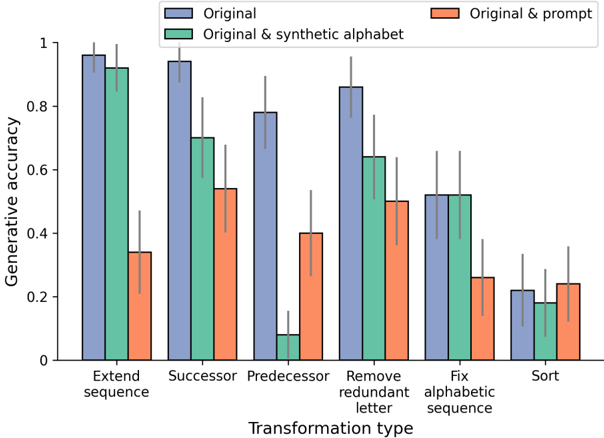
## Grouped Bar Chart: Generative Accuracy by Transformation Type
### Overview
This is a grouped bar chart with error bars, illustrating the performance (generative accuracy) of three different model conditions across six distinct sequence transformation tasks. The chart compares the "Original" model against two modified versions: one augmented with a "synthetic alphabet" and another augmented with a "prompt."
### Components/Axes
* **Chart Type:** Grouped bar chart with error bars.
* **X-Axis (Horizontal):** Labeled **"Transformation type"**. It contains six categorical groups:
1. Extend sequence
2. Successor
3. Predecessor
4. Remove redundant letter
5. Fix alphabetic sequence
6. Sort
* **Y-Axis (Vertical):** Labeled **"Generative accuracy"**. The scale is linear, ranging from 0 to 1, with major tick marks at 0.0, 0.2, 0.4, 0.6, 0.8, and 1.0.
* **Legend:** Positioned at the top center of the chart. It defines three data series by color:
* **Blue (Left bar in each group):** "Original"
* **Green (Middle bar in each group):** "Original & synthetic alphabet"
* **Orange (Right bar in each group):** "Original & prompt"
* **Error Bars:** Each bar has a vertical black line extending above and below its top, indicating variability or confidence intervals around the mean accuracy.
### Detailed Analysis
Below are the approximate generative accuracy values for each condition across all transformation types. Values are estimated from the bar heights relative to the y-axis. Error bar ranges are also approximate.
**1. Extend sequence**
* **Original (Blue):** ~0.96 (Error bar range: ~0.92 to 1.0)
* **Original & synthetic alphabet (Green):** ~0.92 (Error bar range: ~0.88 to 0.96)
* **Original & prompt (Orange):** ~0.34 (Error bar range: ~0.22 to 0.46)
**2. Successor**
* **Original (Blue):** ~0.95 (Error bar range: ~0.90 to 1.0)
* **Original & synthetic alphabet (Green):** ~0.70 (Error bar range: ~0.58 to 0.82)
* **Original & prompt (Orange):** ~0.54 (Error bar range: ~0.40 to 0.68)
**3. Predecessor**
* **Original (Blue):** ~0.78 (Error bar range: ~0.68 to 0.88)
* **Original & synthetic alphabet (Green):** ~0.08 (Error bar range: ~0.02 to 0.14)
* **Original & prompt (Orange):** ~0.40 (Error bar range: ~0.26 to 0.54)
**4. Remove redundant letter**
* **Original (Blue):** ~0.86 (Error bar range: ~0.78 to 0.94)
* **Original & synthetic alphabet (Green):** ~0.64 (Error bar range: ~0.52 to 0.76)
* **Original & prompt (Orange):** ~0.50 (Error bar range: ~0.38 to 0.62)
**5. Fix alphabetic sequence**
* **Original (Blue):** ~0.52 (Error bar range: ~0.40 to 0.64)
* **Original & synthetic alphabet (Green):** ~0.52 (Error bar range: ~0.40 to 0.64)
* **Original & prompt (Orange):** ~0.26 (Error bar range: ~0.14 to 0.38)
**6. Sort**
* **Original (Blue):** ~0.22 (Error bar range: ~0.10 to 0.34)
* **Original & synthetic alphabet (Green):** ~0.18 (Error bar range: ~0.08 to 0.28)
* **Original & prompt (Orange):** ~0.24 (Error bar range: ~0.12 to 0.36)
### Key Observations
1. **Dominance of the Original Model:** The "Original" (blue) condition achieves the highest or tied-for-highest accuracy in 5 out of 6 tasks. Its performance is particularly strong on "Extend sequence" and "Successor."
2. **Detrimental Effect of Prompts:** The "Original & prompt" (orange) condition consistently underperforms the "Original" model across all tasks. The performance drop is most severe for "Extend sequence" (from ~0.96 to ~0.34).
3. **Mixed Impact of Synthetic Alphabet:** The "Original & synthetic alphabet" (green) condition shows highly variable results.
* It performs nearly as well as the Original on "Extend sequence" and matches it exactly on "Fix alphabetic sequence."
* It causes a catastrophic failure on the "Predecessor" task, dropping accuracy to near zero (~0.08).
* It generally performs worse than the Original but better than the prompt-augmented version on other tasks.
4. **Task Difficulty Gradient:** There is a clear trend in overall task difficulty. "Extend sequence" and "Successor" appear to be the easiest tasks (high accuracy for the Original model), while "Sort" and "Fix alphabetic sequence" are the most challenging (low accuracy for all conditions).
5. **High Variability:** The error bars are substantial for many data points, indicating significant variance in model performance across different trials or samples for a given task and condition.
### Interpretation
This chart demonstrates the impact of different augmentation strategies on a model's ability to perform symbolic sequence transformations. The data suggests several key insights:
* **Baseline Competence:** The "Original" model possesses a strong inherent capability for sequence manipulation, especially for forward-looking tasks like extension and finding successors.
* **Prompting as Interference:** Adding a prompt ("Original & prompt") appears to act as a significant source of noise or distraction, severely degrading performance. This could indicate that the prompting mechanism interferes with the model's internal reasoning process for these specific algorithmic tasks.
* **Synthetic Alphabet as a Specialized Tool:** Introducing a "synthetic alphabet" has a task-dependent effect. It is benign or helpful for tasks closely related to sequence structure ("Extend," "Fix alphabetic sequence") but is profoundly harmful for the "Predecessor" task. This suggests the synthetic alphabet may reconfigure the model's internal representation in a way that breaks its understanding of reverse sequence relationships.
* **The "Predecessor" Anomaly:** The near-zero performance of the synthetic alphabet condition on the "Predecessor" task is the most striking outlier. It indicates a fundamental incompatibility between the augmented representation and the cognitive operation required to identify a preceding element in a sequence.
* **Generalization Gap:** The low accuracy on "Sort" across all conditions highlights a potential limitation in the model's ability to handle more complex, global sequence reordering operations compared to local transformations.
In summary, the chart reveals that augmenting a model's input or representation is not universally beneficial. The "Original" model's architecture is already well-suited for these tasks, and modifications can introduce significant interference, with effects that are highly sensitive to the specific nature of the transformation required.
DECODING INTELLIGENCE...