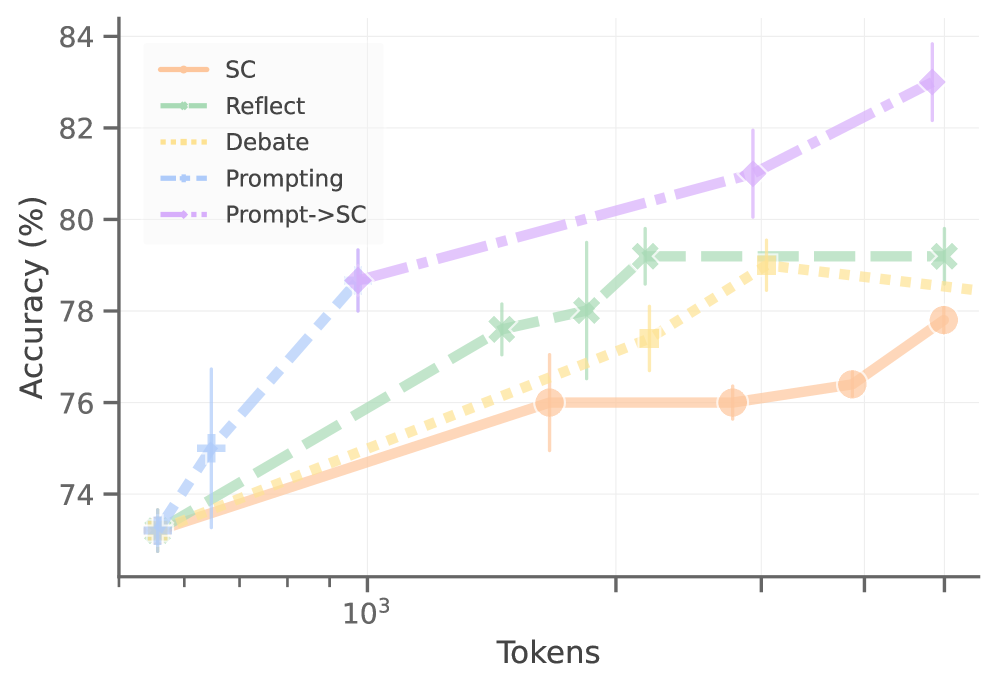
# Technical Document Extraction: Accuracy vs. Tokens Line Graph
## Axes and Labels
- **X-axis**:
- Label: "Tokens"
- Scale: Logarithmic (10³ to 10⁴)
- Tick Marks: 10³, 10⁴, 10⁵
- **Y-axis**:
- Label: "Accuracy (%)"
- Range: 72% to 84%
- Tick Marks: 72%, 74%, 76%, 78%, 80%, 82%, 84%
## Legend
- **Methods and Corresponding Line Styles/Colors**:
1. **SC**: Solid orange line
2. **Reflect**: Dashed green line
3. **Debate**: Dotted yellow line
4. **Prompting**: Dash-dot blue line
5. **Prompt->SC**: Dash-dot purple line
## Data Points and Error Bars
Each method is represented by markers at specific token counts (10³, 10⁴, 10⁵) with error bars indicating variability. Key values:
- **SC**:
- 10³: 73.5% (±0.5%)
- 10⁴: 76.0% (±0.3%)
- 10⁵: 77.8% (±0.4%)
- **Reflect**:
- 10³: 73.2% (±0.6%)
- 10⁴: 77.5% (±0.5%)
- 10⁵: 79.2% (±0.3%)
- **Debate**:
- 10³: 73.1% (±0.7%)
- 10⁴: 78.1% (±0.4%)
- 10⁵: 78.6% (±0.5%)
- **Prompting**:
- 10³: 73.3% (±0.6%)
- 10⁴: 78.7% (±0.5%)
- 10⁵: 76.9% (±0.7%)
- **Prompt->SC**:
- 10³: 73.4% (±0.5%)
- 10⁴: 78.9% (±0.4%)
- 10⁵: 82.9% (±0.6%)
## Key Trends
1. **General Accuracy Increase**:
- All methods show upward trends in accuracy as token count increases from 10³ to 10⁵, except **Prompting**, which declines at 10⁵.
2. **Highest Performance**:
- **Prompt->SC** achieves the highest accuracy (82.9% at 10⁵), outperforming all other methods.
3. **Stability**:
- **SC** and **Reflect** exhibit relatively stable accuracy across token counts, with smaller error margins.
4. **Volatility**:
- **Prompting** shows significant variability, particularly at 10⁵, where accuracy drops sharply.
## Cross-Reference Validation
- Legend labels and line styles/colors are consistent across the graph. For example:
- **SC** (solid orange) aligns with its data points and error bars.
- **Prompt->SC** (dash-dot purple) matches its upward trajectory and highest accuracy at 10⁵.
## Summary
The graph illustrates the relationship between token count and accuracy for five methods. **Prompt->SC** demonstrates the most significant improvement, while **Prompting** underperforms at higher token counts. Error bars highlight variability, with **Prompting** showing the greatest instability.