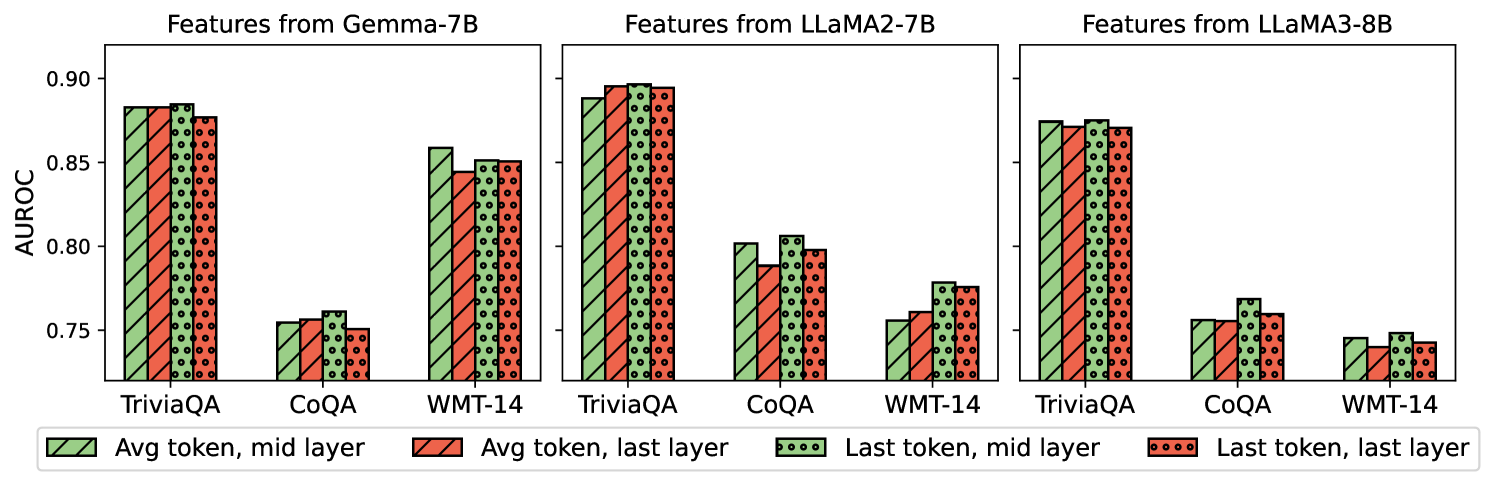
## Bar Chart: AUROC Comparison Across Models and Features
### Overview
The image is a grouped bar chart comparing the Area Under the Receiver Operating Characteristic curve (AUROC) for three language models (Gemma-7B, LLaMA2-7B, LLaMA3-8B) across three datasets (TriviaQA, CoQA, WMT-14). Four feature extraction methods are compared:
1. **Avg token, mid layer** (solid green)
2. **Avg token, last layer** (striped red)
3. **Last token, mid layer** (dotted green)
4. **Last token, last layer** (dotted red)
### Components/Axes
- **X-axis**: Datasets (TriviaQA, CoQA, WMT-14)
- **Y-axis**: AUROC values (0.75–0.90)
- **Legend**: Located at the bottom, mapping colors/patterns to feature extraction methods.
- **Model Sections**: Three vertical groupings (left: Gemma-7B, center: LLaMA2-7B, right: LLaMA3-8B).
### Detailed Analysis
#### Gemma-7B
- **TriviaQA**:
- Avg token, mid layer: ~0.88
- Avg token, last layer: ~0.87
- Last token, mid layer: ~0.88
- Last token, last layer: ~0.87
- **CoQA**:
- Avg token, mid layer: ~0.76
- Avg token, last layer: ~0.76
- Last token, mid layer: ~0.77
- Last token, last layer: ~0.75
- **WMT-14**:
- Avg token, mid layer: ~0.86
- Avg token, last layer: ~0.85
- Last token, mid layer: ~0.86
- Last token, last layer: ~0.85
#### LLaMA2-7B
- **TriviaQA**:
- Avg token, mid layer: ~0.89
- Avg token, last layer: ~0.89
- Last token, mid layer: ~0.89
- Last token, last layer: ~0.89
- **CoQA**:
- Avg token, mid layer: ~0.80
- Avg token, last layer: ~0.79
- Last token, mid layer: ~0.81
- Last token, last layer: ~0.80
- **WMT-14**:
- Avg token, mid layer: ~0.77
- Avg token, last layer: ~0.76
- Last token, mid layer: ~0.78
- Last token, last layer: ~0.77
#### LLaMA3-8B
- **TriviaQA**:
- Avg token, mid layer: ~0.88
- Avg token, last layer: ~0.87
- Last token, mid layer: ~0.88
- Last token, last layer: ~0.87
- **CoQA**:
- Avg token, mid layer: ~0.76
- Avg token, last layer: ~0.75
- Last token, mid layer: ~0.77
- Last token, last layer: ~0.75
- **WMT-14**:
- Avg token, mid layer: ~0.74
- Avg token, last layer: ~0.73
- Last token, mid layer: ~0.75
- Last token, last layer: ~0.74
### Key Observations
1. **TriviaQA Dominance**: All models achieve highest AUROC on TriviaQA, suggesting it is the most discriminative dataset.
2. **Feature Method Trends**:
- **Avg token, mid layer** consistently outperforms other methods across models.
- **Last token, last layer** underperforms compared to other feature combinations.
3. **Model Performance**:
- LLaMA2-7B achieves the highest AUROC values overall.
- LLaMA3-8B and Gemma-7B show similar performance, with LLaMA3-8B slightly trailing in CoQA/WMT-14.
4. **Dataset Variance**: CoQA and WMT-14 exhibit lower AUROC values, indicating weaker model performance on these tasks.
### Interpretation
The data suggests that **TriviaQA** is the most effective dataset for evaluating these models, likely due to its focus on factual knowledge. Feature extraction methods involving **average token representations from mid layers** yield the best results, implying that distributed semantic information (rather than isolated tokens or late-layer features) is critical for performance. Larger models (e.g., LLaMA3-8B) outperform smaller ones, but the gap narrows in CoQA/WMT-14, where all models struggle. The underperformance of "last token, last layer" features may indicate overfitting or reduced generalization in late-layer representations.
### Spatial Grounding
- **Legend**: Bottom-center, aligned with x-axis labels.
- **Model Sections**: Vertically stacked, with Gemma-7B (left), LLaMA2-7B (center), LLaMA3-8B (right).
- **Bar Order**: Within each model section, bars are ordered left-to-right as TriviaQA, CoQA, WMT-14.
### Component Isolation
- **Header**: Model titles (Gemma-7B, LLaMA2-7B, LLaMA3-8B) above each section.
- **Main Chart**: Grouped bars for datasets and feature methods.
- **Footer**: AUROC axis (y-axis) and dataset labels (x-axis).
### Content Details
- **TriviaQA Bars**: Tallest across all models, with AUROC values clustered near 0.88–0.89.
- **CoQA Bars**: Shortest, with values ~0.75–0.81.
- **WMT-14 Bars**: Intermediate, ~0.74–0.86.
### Notable Anomalies
- **LLaMA2-7B CoQA**: Last token, mid layer (dotted green) slightly outperforms avg token, last layer (striped red), contradicting the general trend.
- **LLaMA3-8B WMT-14**: Avg token, mid layer (solid green) is marginally better than last token, mid layer (dotted green), but the difference is minimal (~0.74 vs. ~0.75).
This analysis highlights the importance of dataset selection and feature extraction strategy in model evaluation, with TriviaQA and mid-layer average tokens emerging as optimal choices.