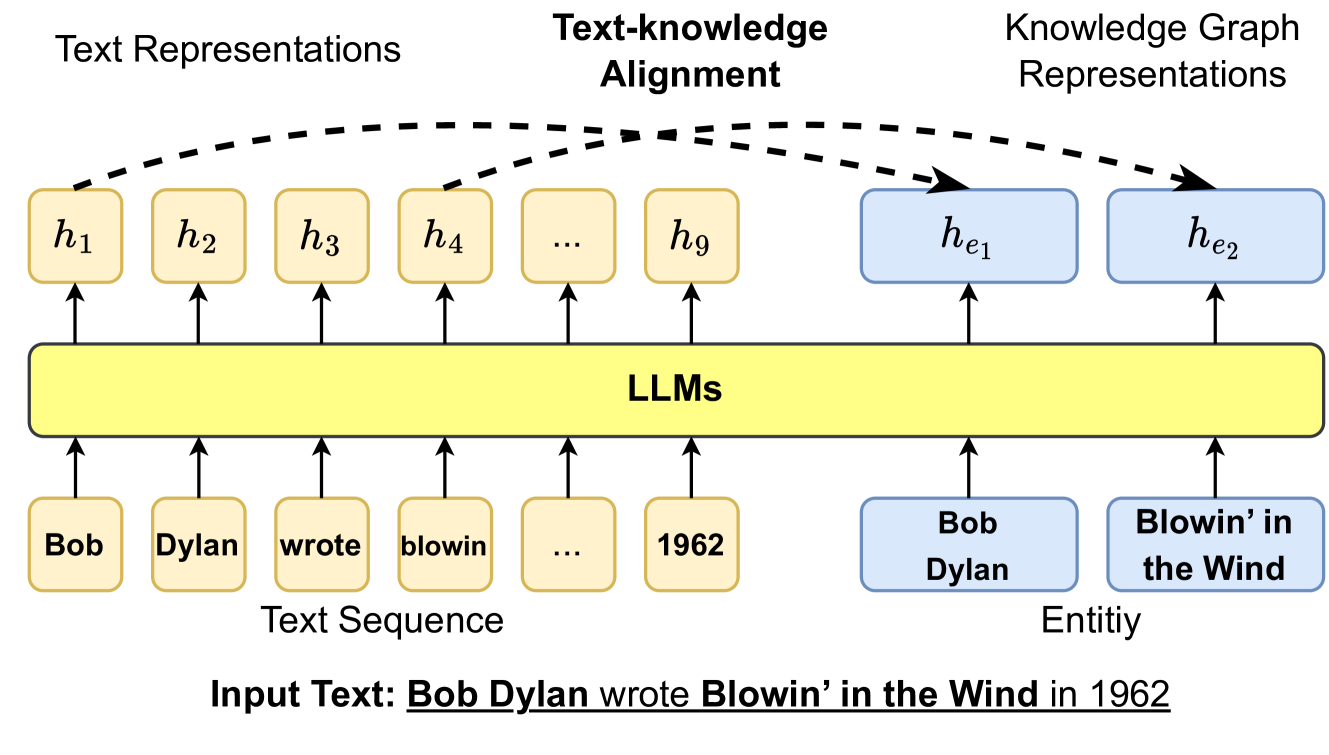
## Diagram: Text-Knowledge Alignment using LLMs
### Overview
The image is a diagram illustrating how Large Language Models (LLMs) perform text-knowledge alignment. It shows the flow of information from an input text sequence to text representations and knowledge graph representations, with LLMs acting as the central processing unit.
### Components/Axes
* **Title:** Text-knowledge Alignment
* **Top-Left:** Text Representations
* Nodes: h1, h2, h3, h4, ..., h9 (yellow rounded rectangles)
* **Top-Right:** Knowledge Graph Representations
* Nodes: he1, he2 (blue rounded rectangles)
* **Center:** LLMs (yellow rounded rectangle)
* **Bottom-Left:** Text Sequence
* Nodes: Bob, Dylan, wrote, blowin, ..., 1962 (yellow rounded rectangles)
* **Bottom-Right:** Entity
* Nodes: Bob Dylan, Blowin' in the Wind (blue rounded rectangles)
* **Input Text:** Bob Dylan wrote Blowin' in the Wind in 1962
### Detailed Analysis
* **Text Sequence to LLMs:** The words "Bob", "Dylan", "wrote", "blowin", "...", and "1962" from the text sequence are represented as individual nodes. Arrows point upwards from each of these nodes to the "LLMs" block, indicating that these words are fed into the LLM.
* **LLMs to Text Representations:** The LLMs process the input text and generate text representations, denoted as h1, h2, h3, h4, ..., h9. Arrows point upwards from the "LLMs" block to each of these nodes.
* **LLMs to Knowledge Graph Representations:** The LLMs also generate knowledge graph representations, denoted as he1 and he2. Arrows point upwards from the "LLMs" block to each of these nodes.
* **Text Representations to Knowledge Graph Representations:** Dashed arrows connect the text representations (h1, h2, h3, h4, h9) to the knowledge graph representations (he1, he2), indicating an alignment or mapping between the two.
* **Entity Representation:** The entities "Bob Dylan" and "Blowin' in the Wind" are represented as nodes, with arrows pointing upwards from the "LLMs" block to each of these nodes.
### Key Observations
* The diagram illustrates a process where an input text is processed by LLMs to generate both text representations and knowledge graph representations.
* The dashed arrows indicate a crucial alignment step between the text representations and the knowledge graph representations.
* The entities extracted from the text are explicitly represented in the knowledge graph.
### Interpretation
The diagram demonstrates how LLMs can be used to bridge the gap between textual information and structured knowledge. By processing the input text, the LLM generates text representations that capture the meaning of the words and phrases. Simultaneously, it extracts entities and relationships from the text to construct a knowledge graph representation. The alignment between these two representations allows the LLM to reason about the text in a more informed and contextualized manner. This process is crucial for tasks such as question answering, information retrieval, and knowledge discovery, where understanding the underlying meaning and relationships within the text is essential. The diagram highlights the ability of LLMs to not only understand text but also to connect it to a broader knowledge base.