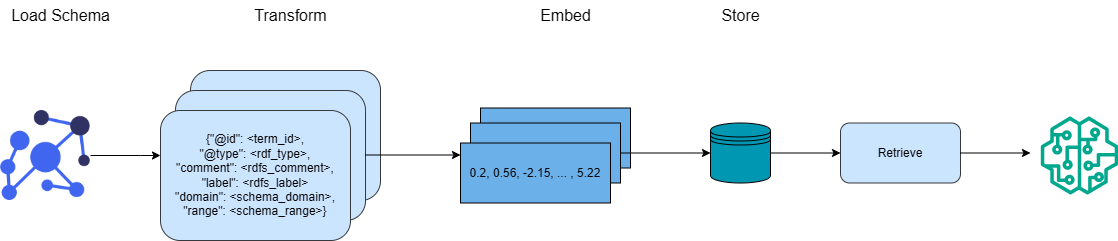
## Data Flow Diagram: Schema Processing Pipeline
### Overview
The image is a data flow diagram illustrating a schema processing pipeline. It depicts the stages of loading, transforming, embedding, storing, and retrieving schema data, culminating in a machine learning application.
### Components/Axes
The diagram consists of the following components, arranged from left to right:
1. **Load Schema:** Represents the initial stage of loading schema data.
2. **Transform:** Represents the transformation of the loaded schema.
3. **Embed:** Represents the embedding of the transformed schema.
4. **Store:** Represents the storage of the embedded schema.
5. **Retrieve:** Represents the retrieval of the stored schema.
Each stage is connected by arrows indicating the flow of data.
### Detailed Analysis or ### Content Details
* **Load Schema:** A blue network graph icon represents the initial schema.
* **Transform:** Three overlapping light blue rounded rectangles contain a JSON-like structure:
```json
{
"@id": <term_id>,
"@type": <rdf_type>,
"comment": <rdfs_comment>,
"label": <rdfs_label>,
"domain": <schema_domain>,
"range": <schema_range>
}
```
* **Embed:** Three overlapping light blue rounded rectangles contain numerical values: "0.2, 0.56, -2.15, ..., 5.22".
* **Store:** A teal cylinder represents a database or storage system.
* **Retrieve:** A light blue rounded rectangle labeled "Retrieve".
* **Final Stage:** A teal brain-like icon with circuit patterns represents a machine learning application.
### Key Observations
The diagram illustrates a sequential process where schema data is loaded, transformed into a structured format (JSON-like), embedded as numerical data, stored, retrieved, and finally used in a machine learning context.
### Interpretation
The diagram outlines a typical workflow for preparing schema data for use in machine learning models. The transformation step likely involves converting the schema into a standardized format. The embedding step converts the schema into a numerical representation suitable for machine learning algorithms. The storage and retrieval steps ensure the data can be accessed and used efficiently. The final stage indicates the application of machine learning to the processed schema data.