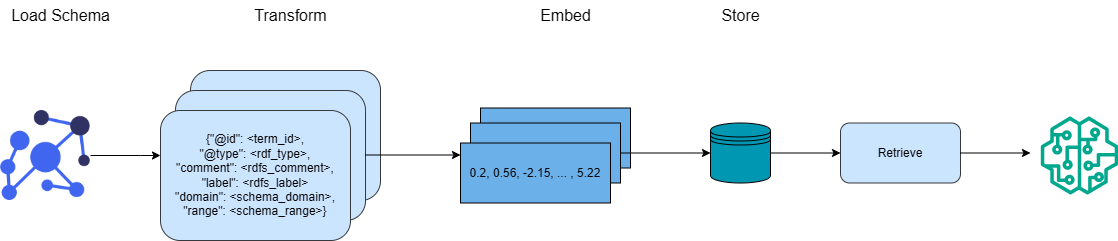
## Flowchart: RDF Data Processing Pipeline
### Overview
The image depicts a multi-stage data processing pipeline with visual components representing data transformation, storage, and retrieval. It combines semantic graph structures with machine learning workflows.
### Components/Axes
1. **Load Schema**
- Visual representation: Network graph with blue circles (entities) and black nodes (relationships)
- Attributes:
- `{@qid": <term_id>`,
- `"@type": <rdf_type>`,
- `"comment": <rdfs_comment>`,
- `"label": <rdfs_label>`,
- `"domain": <schema_domain>`,
- `"range": <schema_range>`
2. **Transform**
- Input: Structured RDF triples from Load Schema
- Output: Embedded numerical vectors (see Embed component)
3. **Embed**
- Process: Conversion of structured data to vector representations
- Sample vector: `[0.2, 0.56, -2.15, ..., 5.22]` (exact values truncated)
4. **Store**
- Component: Teal-colored cylindrical database icon
5. **Retrieve**
- Component: Light blue rectangular retrieval box
6. **Neural Network**
- Final output: Green stylized neural network diagram
### Detailed Analysis
1. **Flow Direction**
- Left-to-right progression from raw schema data to machine learning output
- Circular arrow at the end suggests iterative processing
2. **Color Coding**
- Blue: Load Schema (semantic graph)
- Light Blue: Transform (structural conversion)
- Dark Blue: Embed (vectorization)
- Teal: Store (database)
- Green: Neural Network (AI model)
3. **Key Data Points**
- Embedding dimension: 6+ elements (truncated vector)
- Schema properties: 6 distinct attributes defined
- Storage: Single database instance shown
### Key Observations
1. The pipeline transforms RDF/RDFS triples into machine-readable vector representations
2. Embedded vectors are stored in a database before being fed into a neural network
3. The process implies integration of semantic web data with deep learning systems
4. Circular arrow indicates potential feedback loop between retrieval and processing
### Interpretation
This architecture represents a knowledge graph processing system where:
1. **Semantic relationships** (Load Schema) are converted into structured RDF triples
2. **Structural data** (Transform) undergoes semantic embedding to create vector representations
3. **Vector storage** in a database enables scalable retrieval
4. **Neural network integration** suggests downstream applications like:
- Entity resolution
- Recommendation systems
- Natural language processing
The pipeline bridges semantic web technologies with modern machine learning, enabling AI systems to process structured knowledge graphs efficiently. The truncation of the embedding vector suggests implementation constraints in production systems.