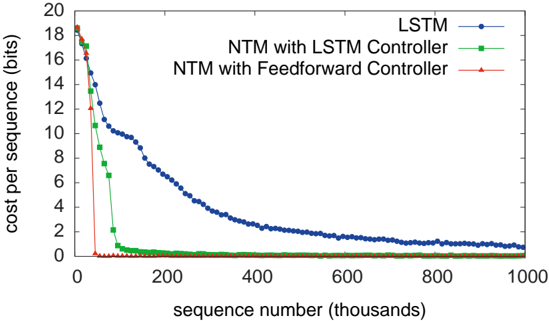
## Line Chart: Training Cost Comparison of Neural Network Architectures
### Overview
The image is a line chart comparing the training performance of three neural network architectures over the course of training. The chart plots the "cost per sequence" (a measure of error or loss) against the number of training sequences processed. The three models compared are a standard LSTM, a Neural Turing Machine (NTM) with an LSTM controller, and an NTM with a Feedforward controller.
### Components/Axes
* **Chart Type:** Line chart with markers.
* **X-Axis:**
* **Label:** `sequence number (thousands)`
* **Scale:** Linear, from 0 to 1000 (representing 0 to 1,000,000 training sequences).
* **Major Ticks:** 0, 200, 400, 600, 800, 1000.
* **Y-Axis:**
* **Label:** `cost per sequence (bits)`
* **Scale:** Linear, from 0 to 20.
* **Major Ticks:** 0, 2, 4, 6, 8, 10, 12, 14, 16, 18, 20.
* **Legend:** Located in the top-right quadrant of the chart area.
* **Blue line with circle markers:** `LSTM`
* **Green line with square markers:** `NTM with LSTM Controller`
* **Red line with triangle markers:** `NTM with Feedforward Controller`
### Detailed Analysis
The chart displays three distinct learning curves, each showing a decrease in cost as training progresses.
1. **LSTM (Blue line with circles):**
* **Trend:** Shows a gradual, steady decline. It starts at a high cost and decreases in a convex curve, flattening out as training continues.
* **Data Points (Approximate):**
* At sequence 0: Cost ~18 bits.
* At sequence 100k: Cost ~12 bits.
* At sequence 200k: Cost ~8 bits.
* At sequence 400k: Cost ~3 bits.
* At sequence 600k: Cost ~1.5 bits.
* At sequence 1000k: Cost ~0.8 bits.
2. **NTM with LSTM Controller (Green line with squares):**
* **Trend:** Shows a very rapid initial decline, followed by a sharp knee and then a very slow, near-flat tail.
* **Data Points (Approximate):**
* At sequence 0: Cost ~18 bits.
* At sequence 50k: Cost drops sharply to ~4 bits.
* At sequence 100k: Cost ~1 bit.
* At sequence 200k: Cost ~0.2 bits.
* From sequence 400k onward: Cost remains very close to 0 bits (approximately 0.1 or less).
3. **NTM with Feedforward Controller (Red line with triangles):**
* **Trend:** Shows the most dramatic and fastest convergence. It plummets almost vertically to near-zero cost.
* **Data Points (Approximate):**
* At sequence 0: Cost ~18 bits.
* At sequence ~25k: Cost has already dropped to near 0 bits.
* For all subsequent sequence numbers (from ~50k to 1000k): Cost is effectively 0 bits, appearing as a flat line on the x-axis.
### Key Observations
* **Convergence Speed:** There is a clear hierarchy in learning speed. The NTM with Feedforward Controller converges fastest, followed by the NTM with LSTM Controller, with the standard LSTM being significantly slower.
* **Final Performance:** Both NTM variants achieve a final cost very close to zero, indicating near-perfect performance on the task. The LSTM, while improving, still has a measurable cost (~0.8 bits) after 1 million sequences.
* **Learning Curve Shape:** The LSTM curve is smooth and gradual. The NTM curves are characterized by an extremely steep initial drop, suggesting they quickly grasp the underlying pattern of the task.
* **Initial Conditions:** All three models start at approximately the same high cost (~18 bits), indicating similar initial performance before training.
### Interpretation
This chart demonstrates the superior sample efficiency and learning capability of the Neural Turing Machine architecture compared to a standard LSTM on the given (but unspecified) sequential task. The key insight is that the NTM's external memory mechanism allows it to learn the task's structure much more rapidly.
* **The Feedforward Controller's Superiority:** The most striking result is that the NTM with a simple Feedforward controller outperforms the one with a more complex LSTM controller. This suggests that for this specific task, the recurrent dynamics of an LSTM controller may be unnecessary or even slightly detrimental, and the core advantage comes from the memory-augmented architecture itself. The Feedforward controller may converge faster due to having fewer parameters to train.
* **Task Implication:** The extremely low final cost (near 0 bits) for the NTMs implies the task likely involves algorithmic or repetitive patterns that can be perfectly stored and retrieved from the NTM's memory matrix. The LSTM, lacking explicit external memory, must approximate this function with its internal state, leading to slower learning and a higher residual error.
* **Practical Significance:** The results argue for the use of memory-augmented neural networks for tasks requiring precise recall over long sequences. The choice of controller (Feedforward vs. LSTM) is an important architectural hyperparameter that can significantly impact training speed.