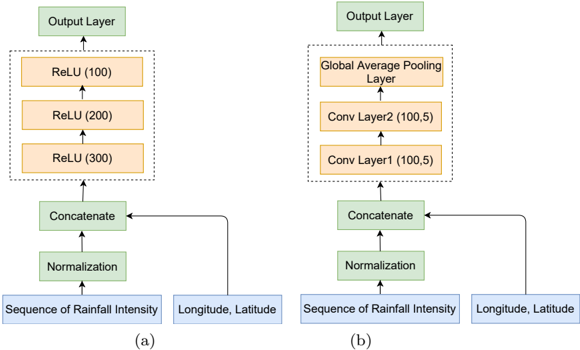
## Diagram: Neural Network Architectures for Rainfall Prediction
### Overview
The image presents two distinct neural network architectures, labeled (a) and (b), designed for rainfall prediction. Both architectures take "Sequence of Rainfall Intensity" and "Longitude, Latitude" as inputs. They differ in their internal layer configurations, particularly in how they process the concatenated input data before producing the final output.
### Components/Axes
**General Components (Shared by both architectures):**
* **Input Layers:** "Sequence of Rainfall Intensity" and "Longitude, Latitude" (both in blue boxes).
* **Normalization Layer:** A green box labeled "Normalization".
* **Concatenate Layer:** A green box labeled "Concatenate".
* **Output Layer:** A green box labeled "Output Layer".
* **Arrows:** Indicate the flow of data through the network.
**Architecture (a) Specific Components:**
* **ReLU Layers:** Three orange boxes labeled "ReLU (300)", "ReLU (200)", and "ReLU (100)" stacked vertically within a dashed-line box.
**Architecture (b) Specific Components:**
* **Convolutional Layers:** Two orange boxes labeled "Conv Layer1 (100,5)" and "Conv Layer2 (100,5)" stacked vertically within a dashed-line box.
* **Global Average Pooling Layer:** An orange box labeled "Global Average Pooling Layer".
### Detailed Analysis
**Architecture (a):**
1. **Input:** "Sequence of Rainfall Intensity" and "Longitude, Latitude" are fed into the network.
2. **Normalization:** The inputs are normalized.
3. **Concatenation:** The normalized inputs are concatenated.
4. **ReLU Layers:** The concatenated data passes through three ReLU (Rectified Linear Unit) layers with 300, 200, and 100 units respectively.
5. **Output:** The final output is generated by the "Output Layer".
**Architecture (b):**
1. **Input:** "Sequence of Rainfall Intensity" and "Longitude, Latitude" are fed into the network.
2. **Normalization:** The inputs are normalized.
3. **Concatenation:** The normalized inputs are concatenated.
4. **Convolutional Layers:** The concatenated data passes through two convolutional layers, "Conv Layer1 (100,5)" and "Conv Layer2 (100,5)". The numbers (100,5) likely represent the number of filters and the kernel size, respectively.
5. **Global Average Pooling:** The output of the convolutional layers is fed into a "Global Average Pooling Layer".
6. **Output:** The final output is generated by the "Output Layer".
**Data Flow:**
* In both architectures, the "Longitude, Latitude" input bypasses the Normalization layer and is directly fed into the Concatenate layer.
* The arrows indicate a clear feedforward flow of data from the inputs to the output layer.
### Key Observations
* Both architectures share the same input and output structure, suggesting they are designed to solve the same rainfall prediction task.
* The primary difference lies in the internal processing of the concatenated input data. Architecture (a) uses a stack of ReLU layers, while architecture (b) employs convolutional layers followed by global average pooling.
* The numbers in parentheses after the layer names (e.g., ReLU (100), Conv Layer1 (100,5)) likely represent the number of units or filters and kernel size in each layer, respectively.
### Interpretation
The two architectures represent different approaches to feature extraction and processing for rainfall prediction. Architecture (a) uses fully connected ReLU layers, which can capture complex relationships between the input features but may be prone to overfitting. Architecture (b) uses convolutional layers, which are better suited for capturing spatial patterns in the data and are generally more robust to overfitting. The global average pooling layer in architecture (b) further reduces the dimensionality of the data and helps to prevent overfitting.
The choice between these architectures would depend on the specific characteristics of the rainfall data and the desired trade-off between accuracy and generalization performance. Architecture (b) is likely to be more effective if the rainfall patterns exhibit spatial correlations, while architecture (a) may be more suitable if the relationships between the input features are more complex and non-spatial.