## Horizontal Bar Chart: Number of Benchmarks by Category
### Overview
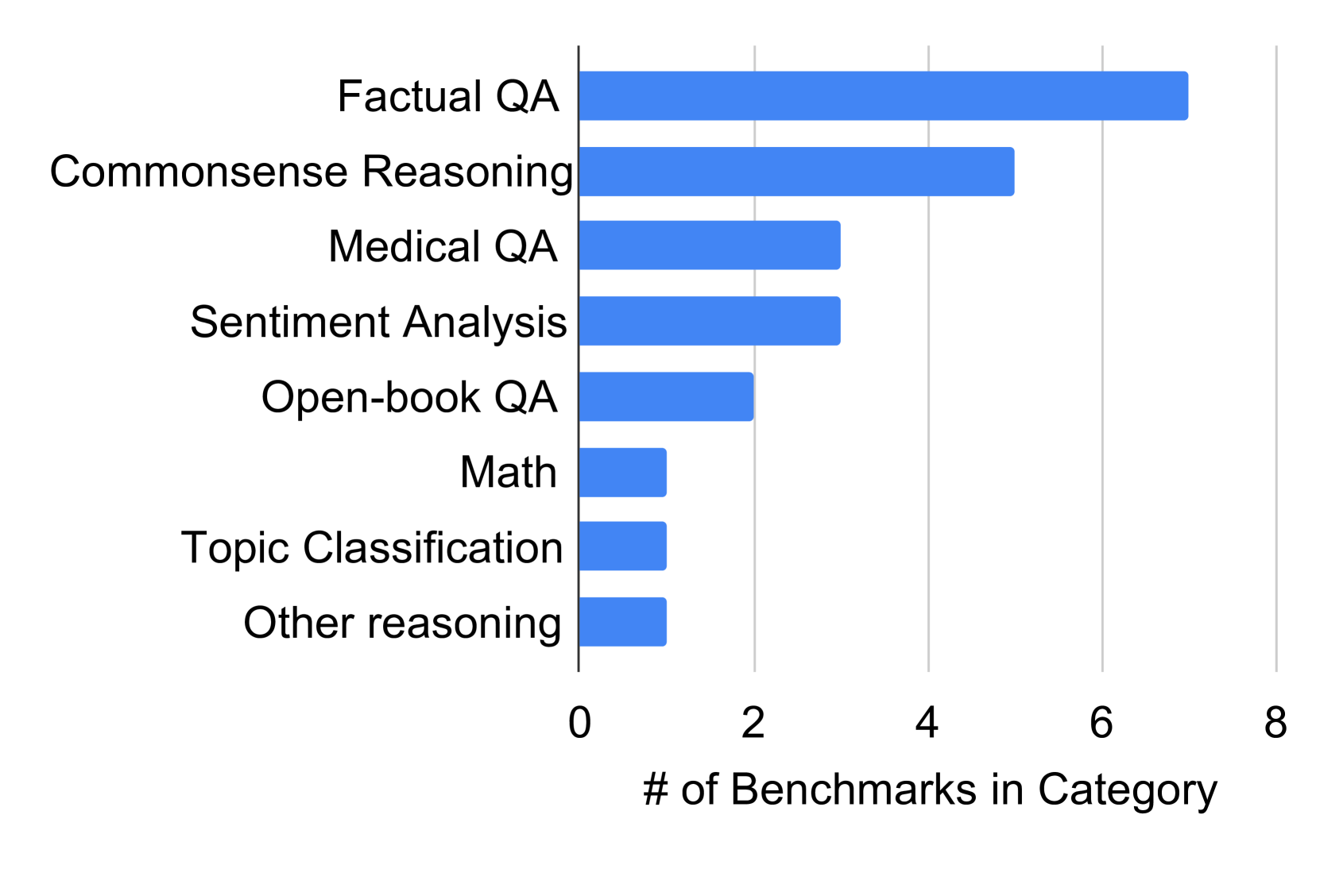
The image displays a horizontal bar chart quantifying the number of benchmarks available across eight distinct categories of natural language processing and reasoning tasks. The chart is sorted in descending order, with the category containing the most benchmarks at the top.
### Components/Axes
* **Chart Type:** Horizontal Bar Chart.
* **Y-Axis (Vertical):** Lists the eight benchmark categories. From top to bottom:
1. Factual QA
2. Commonsense Reasoning
3. Medical QA
4. Sentiment Analysis
5. Open-book QA
6. Math
7. Topic Classification
8. Other reasoning
* **X-Axis (Horizontal):** Labeled "# of Benchmarks in Category". The axis has major tick marks and numerical labels at 0, 2, 4, 6, and 8. Vertical grid lines extend from these ticks.
* **Legend:** Not present. The chart represents a single data series (count of benchmarks).
* **Visual Elements:** All bars are a uniform medium blue color. The chart has a clean, white background with light gray grid lines.
### Detailed Analysis
The length of each bar corresponds to the approximate number of benchmarks in that category. Reading from the x-axis:
| Category | Approximate Number of Benchmarks |
| :--- | :--- |
| Factual QA | 7 |
| Commonsense Reasoning | 5 |
| Medical QA | 3 |
| Sentiment Analysis | 3 |
| Open-book QA | 2 |
| Math | 1 |
| Topic Classification | 1 |
| Other reasoning | 1 |
**Trend Verification:** The visual trend is a clear, stepwise decrease in bar length from top to bottom. The first bar (Factual QA) is the longest, and the final three bars (Math, Topic Classification, Other reasoning) are the shortest and of equal length.
### Key Observations
* **Dominant Category:** "Factual QA" has the highest number of benchmarks (7), which is 40% more than the next category.
* **Secondary Tier:** "Commonsense Reasoning" (5) forms a distinct second tier.
* **Mid-Range Cluster:** "Medical QA" and "Sentiment Analysis" are tied with 3 benchmarks each.
* **Lower Tier:** "Open-book QA" has 2 benchmarks.
* **Minimal Representation:** Three categories—"Math," "Topic Classification," and "Other reasoning"—are tied for the fewest benchmarks, with only 1 each.
* **Distribution:** The data is right-skewed, with a heavy concentration of benchmarks in QA and reasoning tasks, and sparse representation in mathematical and classification tasks.
### Interpretation
This chart provides a snapshot of the benchmark landscape for evaluating AI models, likely in the domain of language understanding and reasoning. The data suggests a strong research and evaluation focus on **factual knowledge retrieval (Factual QA)** and **everyday reasoning (Commonsense Reasoning)**, as these areas have the most developed suites of tests.
The relatively lower number of benchmarks for **Medical QA** and **Sentiment Analysis** might indicate these are more specialized or mature fields where fewer, well-established benchmarks are used. The very low count for **Math** is notable, as it suggests a potential gap or a different evaluation paradigm (e.g., using standardized math competition problems rather than a diverse set of "benchmarks" in the same sense as QA tasks). The "Other reasoning" category being minimal implies the listed categories capture the vast majority of benchmarked tasks.
Overall, the chart highlights where the AI evaluation community has invested the most effort in creating standardized tests, pointing to perceived priorities and possibly areas where model capabilities are most actively measured and compared.