TECHNICAL ASSET FINGERPRINT
ee4948f435c89e9f6477c167
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
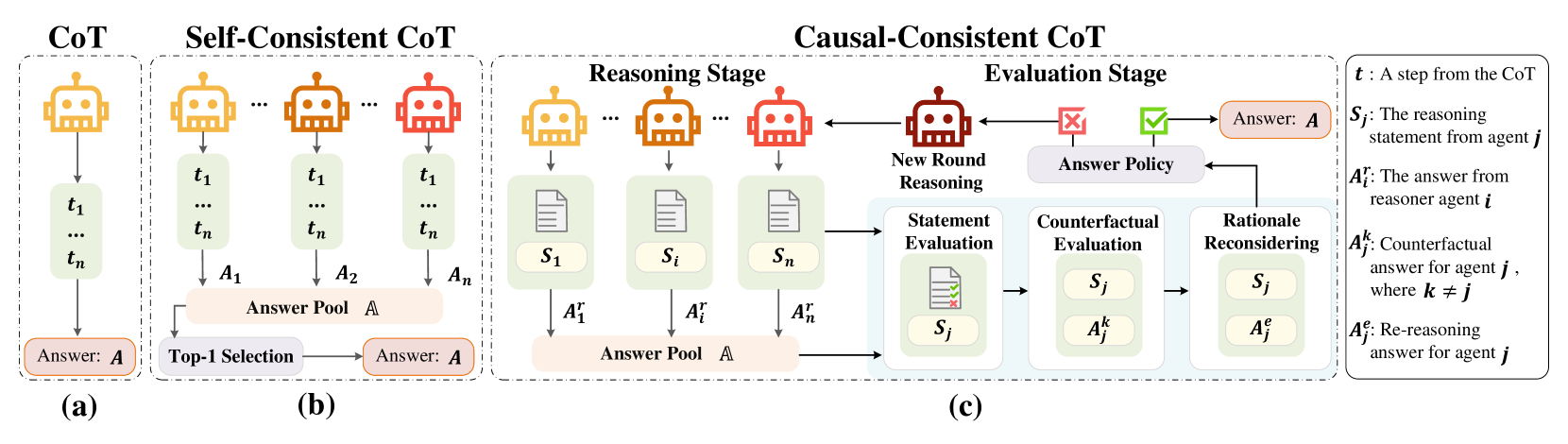
## Diagram: Comparison of Chain-of-Thought (CoT) Reasoning Methods
### Overview
The image is a technical diagram illustrating and comparing three distinct methodologies for generating answers using Chain-of-Thought (CoT) reasoning in AI systems. The diagram is divided into three main panels, labeled (a), (b), and (c), each representing a different approach: standard CoT, Self-Consistent CoT, and Causal-Consistent CoT. A legend on the far right defines the symbolic notation used throughout the diagram.
### Components/Axes
The diagram is structured horizontally into three primary sections, each enclosed in a dashed box.
1. **Panel (a) - CoT (Leftmost):**
* **Header:** "CoT"
* **Components:** A single yellow robot icon representing a reasoning agent. An arrow points down to a vertical list of steps labeled `t₁`, `...`, `tₙ`. A final arrow points to a box labeled "Answer: **A**".
2. **Panel (b) - Self-Consistent CoT (Center-Left):**
* **Header:** "Self-Consistent CoT"
* **Components:** Multiple robot icons (two yellow, one orange, one red) representing multiple reasoning agents. Each agent generates its own sequence of steps (`t₁ ... tₙ`) leading to individual answers (`A₁`, `A₂`, `...`, `Aₙ`). These answers feed into a central "Answer Pool **A**". An arrow from the pool points to a "Top-1 Selection" process, which outputs the final "Answer: **A**".
3. **Panel (c) - Causal-Consistent CoT (Center-Right to Right):**
* **Header:** "Causal-Consistent CoT"
* **Sub-sections:** This panel is further divided into a "Reasoning Stage" and an "Evaluation Stage".
* **Reasoning Stage:**
* Multiple robot icons (yellow, orange, red) generate reasoning statements (`S₁`, `...`, `Sᵢ`, `...`, `Sₙ`) and corresponding answers (`A₁ʳ`, `...`, `Aᵢʳ`, `...`, `Aₙʳ`).
* These answers populate an "Answer Pool **A**".
* **Evaluation Stage:**
* A red robot icon labeled "New Round Reasoning" is central.
* A flowchart processes statements and answers from the pool:
1. **Statement Evaluation:** Evaluates a statement `Sⱼ` (shown with a document icon containing a green check and red cross).
2. **Counterfactual Evaluation:** Considers the statement `Sⱼ` alongside a counterfactual answer `Aⱼᵏ` (where `k ≠ j`).
3. **Rationale Reconsidering:** Reconsiders the statement `Sⱼ` with a re-reasoning answer `Aⱼᵉ`.
* The output of this evaluation feeds into an "Answer Policy" (shown with a red cross and green checkmark icon).
* The "Answer Policy" determines the final "Answer: **A**" and can trigger a "New Round Reasoning" loop back to the reasoning stage.
4. **Legend (Far Right):**
* A box containing definitions for the symbolic notation:
* `t`: A step from the CoT
* `Sⱼ`: The reasoning statement from agent `j`
* `Aᵢʳ`: The answer from reasoner agent `i`
* `Aⱼᵏ`: Counterfactual answer for agent `j`, where `k ≠ j`
* `Aⱼᵉ`: Re-reasoning answer for agent `j`
### Detailed Analysis
The diagram visually maps the flow of information and decision-making in each method.
* **CoT (a):** A simple, linear pipeline. One agent performs a sequence of reasoning steps (`t₁` to `tₙ`) to produce a single answer `A`.
* **Self-Consistent CoT (b):** Introduces parallelism and aggregation. Multiple independent agents (`A₁` through `Aₙ`) generate diverse reasoning paths and answers. These are collected in a pool, and a "Top-1 Selection" mechanism (e.g., majority vote) chooses the final answer `A`. This method aims for robustness through diversity.
* **Causal-Consistent CoT (c):** Introduces a complex, iterative evaluation loop.
* **Reasoning Stage:** Similar to Self-Consistent, multiple agents generate statements (`S`) and answers (`Aʳ`).
* **Evaluation Stage:** This is the core innovation. It doesn't just select an answer; it critically evaluates the *reasoning statements* (`Sⱼ`) themselves.
* **Statement Evaluation:** Assesses the validity of a statement.
* **Counterfactual Evaluation:** Tests the statement against alternative, counterfactual answers (`Aⱼᵏ`), probing for causal consistency.
* **Rationale Reconsidering:** Allows for re-reasoning (`Aⱼᵉ`) based on the evaluation.
* The "Answer Policy" uses the results of this multi-faceted evaluation to either finalize an answer or trigger a new round of reasoning, creating a feedback loop for refinement.
### Key Observations
1. **Increasing Complexity:** The methods progress from a single linear path (CoT), to parallel paths with selection (Self-Consistent), to parallel paths with deep, iterative evaluation and feedback (Causal-Consistent).
2. **Shift from Answer-Centric to Reasoning-Centric:** While CoT and Self-Consistent CoT focus on generating and selecting final *answers* (`A`), Causal-Consistent CoT places primary emphasis on evaluating the underlying *reasoning statements* (`Sⱼ`).
3. **Introduction of Counterfactuals:** The Causal-Consistent method uniquely incorporates "Counterfactual Evaluation" (`Aⱼᵏ`), explicitly testing reasoning against alternative scenarios to ensure causal robustness.
4. **Feedback Loop:** Only the Causal-Consistent method features a cyclical process ("New Round Reasoning"), allowing the system to iteratively improve its reasoning based on internal evaluation.
5. **Color Coding:** Robots are colored yellow, orange, and red, likely to visually distinguish different agents or reasoning instances, though the specific meaning of each color is not defined in the legend.
### Interpretation
This diagram illustrates an evolution in AI reasoning strategies aimed at improving reliability and robustness.
* **CoT** represents the foundational approach of breaking down problems into steps.
* **Self-Consistent CoT** addresses the brittleness of a single reasoning path by leveraging multiple attempts and consensus, akin to "wisdom of the crowd" for a single model.
* **Causal-Consistent CoT** proposes a more sophisticated, self-critical framework. It moves beyond aggregating outputs to actively *auditing the reasoning process itself*. By evaluating statements, testing them against counterfactuals, and allowing for re-reasoning, it seeks to ensure that the final answer is not just statistically likely but *causally sound* and logically consistent. The "Answer Policy" acts as a gatekeeper informed by this deep audit.
The progression suggests a research direction focused on building AI systems that can internally validate and correct their own reasoning chains, moving towards more trustworthy and explainable AI. The complexity of the Causal-Consistent method implies a trade-off between computational cost and the robustness of the final answer.
DECODING INTELLIGENCE...