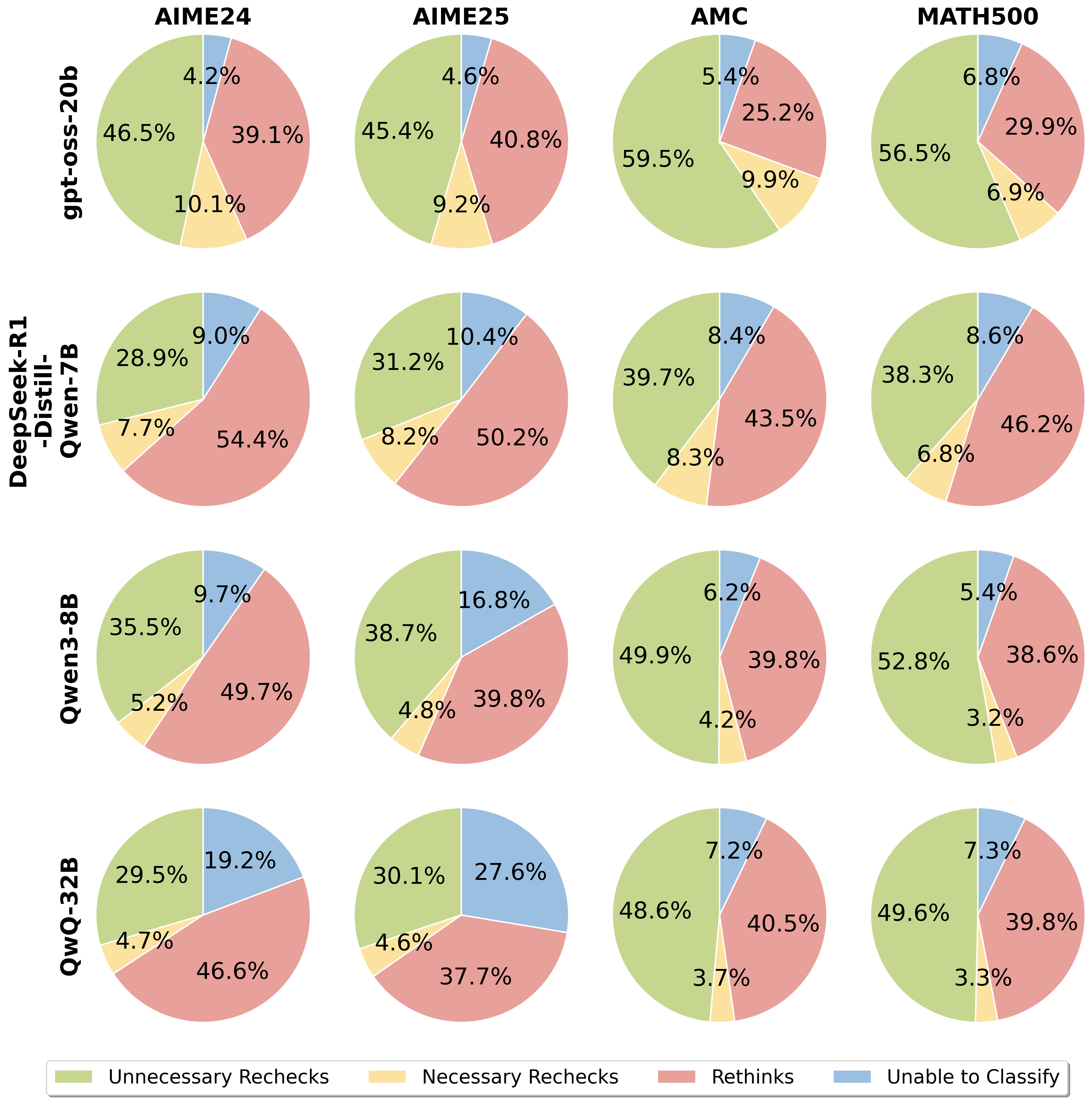
## Pie Chart Comparison: Model Performance on Different Datasets
### Overview
The image presents a series of pie charts comparing the performance of different language models (gpt-oss-20b, DeepSeek-R1-Distill-Qwen-7B, Qwen3-8B, and QwQ-32B) on four datasets (AIME24, AIME25, AMC, and MATH500). Each pie chart represents the distribution of model behavior, categorized into "Unnecessary Rechecks," "Necessary Rechecks," "Rethinks," and "Unable to Classify."
### Components/Axes
* **Rows (Models):**
* gpt-oss-20b (Top Row)
* DeepSeek-R1-Distill-Qwen-7B (Second Row)
* Qwen3-8B (Third Row)
* QwQ-32B (Bottom Row)
* **Columns (Datasets):**
* AIME24 (Leftmost Column)
* AIME25 (Second Column)
* AMC (Third Column)
* MATH500 (Rightmost Column)
* **Pie Chart Categories (Legend - Bottom):**
* **Unnecessary Rechecks:** Light Green
* **Necessary Rechecks:** Light Yellow
* **Rethinks:** Light Red
* **Unable to Classify:** Light Blue
### Detailed Analysis or ### Content Details
**Row 1: gpt-oss-20b**
* **AIME24:**
* Unnecessary Rechecks: 46.5%
* Necessary Rechecks: 10.1%
* Rethinks: 39.1%
* Unable to Classify: 4.2%
* **AIME25:**
* Unnecessary Rechecks: 45.4%
* Necessary Rechecks: 9.2%
* Rethinks: 40.8%
* Unable to Classify: 4.6%
* **AMC:**
* Unnecessary Rechecks: 59.5%
* Necessary Rechecks: 9.9%
* Rethinks: 25.2%
* Unable to Classify: 5.4%
* **MATH500:**
* Unnecessary Rechecks: 56.5%
* Necessary Rechecks: 6.9%
* Rethinks: 29.9%
* Unable to Classify: 6.8%
**Row 2: DeepSeek-R1-Distill-Qwen-7B**
* **AIME24:**
* Unnecessary Rechecks: 28.9%
* Necessary Rechecks: 7.7%
* Rethinks: 54.4%
* Unable to Classify: 9.0%
* **AIME25:**
* Unnecessary Rechecks: 31.2%
* Necessary Rechecks: 8.2%
* Rethinks: 50.2%
* Unable to Classify: 10.4%
* **AMC:**
* Unnecessary Rechecks: 39.7%
* Necessary Rechecks: 8.3%
* Rethinks: 43.5%
* Unable to Classify: 8.4%
* **MATH500:**
* Unnecessary Rechecks: 38.3%
* Necessary Rechecks: 6.8%
* Rethinks: 46.2%
* Unable to Classify: 8.6%
**Row 3: Qwen3-8B**
* **AIME24:**
* Unnecessary Rechecks: 35.5%
* Necessary Rechecks: 5.2%
* Rethinks: 49.7%
* Unable to Classify: 9.7%
* **AIME25:**
* Unnecessary Rechecks: 38.7%
* Necessary Rechecks: 4.8%
* Rethinks: 39.8%
* Unable to Classify: 16.8%
* **AMC:**
* Unnecessary Rechecks: 49.9%
* Necessary Rechecks: 4.2%
* Rethinks: 39.8%
* Unable to Classify: 6.2%
* **MATH500:**
* Unnecessary Rechecks: 52.8%
* Necessary Rechecks: 3.2%
* Rethinks: 38.6%
* Unable to Classify: 5.4%
**Row 4: QwQ-32B**
* **AIME24:**
* Unnecessary Rechecks: 29.5%
* Necessary Rechecks: 4.7%
* Rethinks: 46.6%
* Unable to Classify: 19.2%
* **AIME25:**
* Unnecessary Rechecks: 30.1%
* Necessary Rechecks: 4.6%
* Rethinks: 37.7%
* Unable to Classify: 27.6%
* **AMC:**
* Unnecessary Rechecks: 48.6%
* Necessary Rechecks: 3.7%
* Rethinks: 40.5%
* Unable to Classify: 7.2%
* **MATH500:**
* Unnecessary Rechecks: 49.6%
* Necessary Rechecks: 3.3%
* Rethinks: 39.8%
* Unable to Classify: 7.3%
### Key Observations
* **gpt-oss-20b:** Generally exhibits a higher percentage of "Unnecessary Rechecks" compared to other models, especially on AMC and MATH500 datasets.
* **DeepSeek-R1-Distill-Qwen-7B:** Shows a significantly higher percentage of "Rethinks" across all datasets compared to other models.
* **Qwen3-8B:** Has a relatively balanced distribution across categories, with a notable increase in "Unable to Classify" on the AIME25 dataset.
* **QwQ-32B:** Displays the highest percentage of "Unable to Classify" on AIME24 and AIME25, suggesting potential difficulties with these datasets.
* Across all models, the percentage of "Necessary Rechecks" is consistently the lowest.
### Interpretation
The pie charts provide insights into the problem-solving strategies and limitations of different language models on various datasets. The "Unnecessary Rechecks" category might indicate inefficient processing or overthinking, while "Rethinks" could reflect the model's ability to correct errors or refine its approach. A high percentage of "Unable to Classify" suggests that the model struggles to understand or process certain types of questions or data.
The data suggests that gpt-oss-20b tends to rely more on unnecessary rechecks, while DeepSeek-R1-Distill-Qwen-7B frequently rethinks its answers. QwQ-32B seems to have difficulty classifying certain inputs, particularly in the AIME datasets. The variations in performance across datasets highlight the importance of dataset-specific model evaluation and optimization.