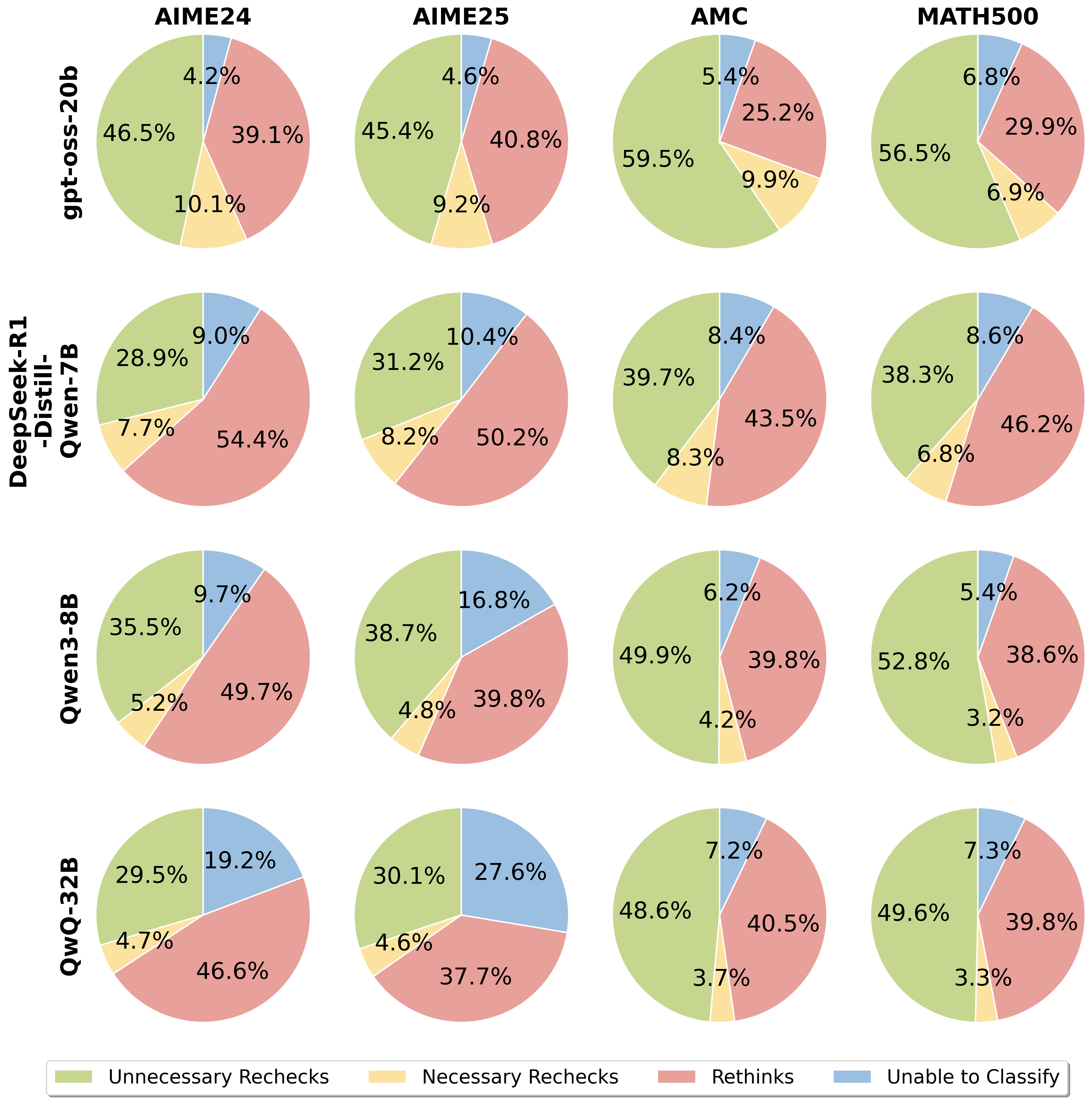
## Grid of Pie Charts: Model Performance Across Datasets and Categories
### Overview
The image displays a 4x4 grid of pie charts comparing model performance across four datasets (AIME24, AIME25, AMC, MATH500) and four categories (gpt-oss-20b, DeepSeek-R1-Distill-Qwen-7B, Qwen3-8B, QwQ-32B). Each pie chart is divided into four colored segments representing:
- **Green**: Unnecessary Rechecks
- **Yellow**: Necessary Rechecks
- **Red**: Rethinks
- **Blue**: Unable to Classify
### Components/Axes
- **X-axis (Categories)**:
- Top row: gpt-oss-20b
- Second row: DeepSeek-R1-Distill-Qwen-7B
- Third row: Qwen3-8B
- Bottom row: QwQ-32B
- **Y-axis (Datasets)**:
- Left column: AIME24
- Second column: AIME25
- Third column: AMC
- Right column: MATH500
- **Legend**: Located at the bottom, with color mappings:
- Green = Unnecessary Rechecks
- Yellow = Necessary Rechecks
- Red = Rethinks
- Blue = Unable to Classify
### Detailed Analysis
#### Dataset: AIME24
- **gpt-oss-20b**:
- Unnecessary Rechecks: 46.5% (green)
- Rethinks: 39.1% (red)
- Necessary Rechecks: 10.1% (yellow)
- Unable to Classify: 4.2% (blue)
- **DeepSeek-R1-Distill-Qwen-7B**:
- Unnecessary Rechecks: 28.9% (green)
- Rethinks: 54.4% (red)
- Necessary Rechecks: 7.7% (yellow)
- Unable to Classify: 9.0% (blue)
- **Qwen3-8B**:
- Unnecessary Rechecks: 35.5% (green)
- Rethinks: 49.7% (red)
- Necessary Rechecks: 5.2% (yellow)
- Unable to Classify: 9.7% (blue)
- **QwQ-32B**:
- Unnecessary Rechecks: 29.5% (green)
- Rethinks: 46.6% (red)
- Necessary Rechecks: 4.7% (yellow)
- Unable to Classify: 19.2% (blue)
#### Dataset: AIME25
- **gpt-oss-20b**:
- Unnecessary Rechecks: 45.4% (green)
- Rethinks: 40.8% (red)
- Necessary Rechecks: 9.2% (yellow)
- Unable to Classify: 4.6% (blue)
- **DeepSeek-R1-Distill-Qwen-7B**:
- Unnecessary Rechecks: 31.2% (green)
- Rethinks: 50.2% (red)
- Necessary Rechecks: 8.2% (yellow)
- Unable to Classify: 10.4% (blue)
- **Qwen3-8B**:
- Unnecessary Rechecks: 38.7% (green)
- Rethinks: 39.8% (red)
- Necessary Rechecks: 4.8% (yellow)
- Unable to Classify: 16.8% (blue)
- **QwQ-32B**:
- Unnecessary Rechecks: 30.1% (green)
- Rethinks: 37.7% (red)
- Necessary Rechecks: 4.6% (yellow)
- Unable to Classify: 27.6% (blue)
#### Dataset: AMC
- **gpt-oss-20b**:
- Unnecessary Rechecks: 59.5% (green)
- Rethinks: 25.2% (red)
- Necessary Rechecks: 9.9% (yellow)
- Unable to Classify: 5.4% (blue)
- **DeepSeek-R1-Distill-Qwen-7B**:
- Unnecessary Rechecks: 39.7% (green)
- Rethinks: 43.5% (red)
- Necessary Rechecks: 8.3% (yellow)
- Unable to Classify: 8.4% (blue)
- **Qwen3-8B**:
- Unnecessary Rechecks: 49.9% (green)
- Rethinks: 39.8% (red)
- Necessary Rechecks: 4.2% (yellow)
- Unable to Classify: 6.2% (blue)
- **QwQ-32B**:
- Unnecessary Rechecks: 48.6% (green)
- Rethinks: 40.5% (red)
- Necessary Rechecks: 3.7% (yellow)
- Unable to Classify: 7.2% (blue)
#### Dataset: MATH500
- **gpt-oss-20b**:
- Unnecessary Rechecks: 56.5% (green)
- Rethinks: 29.9% (red)
- Necessary Rechecks: 6.9% (yellow)
- Unable to Classify: 6.8% (blue)
- **DeepSeek-R1-Distill-Qwen-7B**:
- Unnecessary Rechecks: 38.3% (green)
- Rethinks: 46.2% (red)
- Necessary Rechecks: 6.8% (yellow)
- Unable to Classify: 8.6% (blue)
- **Qwen3-8B**:
- Unnecessary Rechecks: 52.8% (green)
- Rethinks: 38.6% (red)
- Necessary Rechecks: 3.2% (yellow)
- Unable to Classify: 5.4% (blue)
- **QwQ-32B**:
- Unnecessary Rechecks: 49.6% (green)
- Rethinks: 39.8% (red)
- Necessary Rechecks: 3.3% (yellow)
- Unable to Classify: 7.3% (blue)
### Key Observations
1. **Unnecessary Rechecks Dominance**:
- The **gpt-oss-20b** category consistently shows the highest Unnecessary Rechecks across all datasets (e.g., 59.5% in AMC).
- **QwQ-32B** models exhibit the lowest Unnecessary Rechecks (29.5% in AIME24).
2. **Rethinks Variability**:
- **DeepSeek-R1-Distill-Qwen-7B** has the highest Rethinks in AIME24 (54.4%) and AIME25 (50.2%).
- **QwQ-32B** models show the lowest Rethinks (37.7% in AIME25).
3. **Unable to Classify Outliers**:
- **QwQ-32B** in AIME25 has the highest "Unable to Classify" rate (27.6%), suggesting potential reliability issues.
- **DeepSeek-R1-Distill-Qwen-7B** in AIME25 has the second-highest (10.4%).
4. **Necessary Rechecks**:
- **QwQ-32B** models have the lowest Necessary Rechecks (3.2–4.8%), indicating fewer corrections.
- **gpt-oss-20b** in AIME24 has the highest (10.1%).
### Interpretation
- **Model Performance Trends**:
- The **gpt-oss-20b** category prioritizes Unnecessary Rechecks, suggesting over-cautiousness or inefficiency in task resolution.
- **DeepSeek-R1-Distill-Qwen-7B** models exhibit high Rethinks, indicating frequent self-correction or uncertainty.
- **QwQ-32B** models show balanced performance but struggle with "Unable to Classify" in AIME25, hinting at task-specific limitations.
- **Dataset-Specific Insights**:
- **AMC** and **MATH500** datasets reveal higher Unnecessary Rechecks for **gpt-oss-20b**, possibly due to complexity or ambiguity in these tasks.
- **AIME24** and **AIME25** datasets highlight **DeepSeek-R1-Distill-Qwen-7B**'s reliance on Rethinks, suggesting iterative refinement is critical for these benchmarks.
- **Anomalies**:
- The **QwQ-32B** model in AIME25 has an unusually high "Unable to Classify" rate (27.6%), which may indicate architectural or training gaps.
- **Qwen3-8B** in AMC has the lowest Necessary Rechecks (4.2%), implying efficient task handling.
This analysis underscores trade-offs between model architectures and their adaptability across datasets, with **gpt-oss-20b** favoring caution and **QwQ-32B** showing mixed reliability.