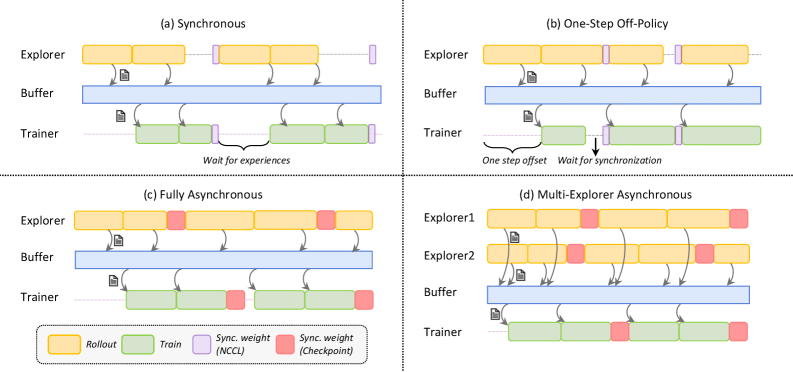
\n
## Diagram: Asynchronous Reinforcement Learning Architectures
### Overview
The image presents a comparative diagram illustrating four different architectures for asynchronous reinforcement learning: Synchronous, One-Step Off-Policy, Fully Asynchronous, and Multi-Explorer Asynchronous. Each architecture is depicted as a timeline with three main components: Explorer, Buffer, and Trainer. The diagram visually represents the flow of data and synchronization mechanisms between these components.
### Components/Axes
The diagram consists of four sub-diagrams labeled (a) through (d), each representing a different architecture. Each sub-diagram has three horizontal lanes representing the Explorer, Buffer, and Trainer. A legend at the bottom-right explains the color-coding:
* **Rollout** (Yellow): Represents the exploration phase.
* **Train** (Green): Represents the training phase.
* **Sync. weight (NCCL)** (Red): Represents weight synchronization using NCCL.
* **Sync. weight (Checkpoint)** (Pink): Represents weight synchronization using Checkpoints.
Arrows indicate the flow of data between components. Text labels describe synchronization mechanisms and delays.
### Detailed Analysis or Content Details
**(a) Synchronous:**
* Explorer: Yellow blocks representing "Rollout" are stacked sequentially.
* Buffer: Blue blocks representing data storage.
* Trainer: Green blocks representing "Train".
* Data flows from Explorer to Buffer, then to Trainer, and back to Explorer.
* Label: "Wait for experiences" indicates a synchronization point.
**(b) One-Step Off-Policy:**
* Explorer: Similar to (a), with yellow "Rollout" blocks.
* Buffer: Blue blocks.
* Trainer: Green blocks.
* Data flow is similar to (a), but with additional labels: "One step offset" and "Wait for synchronization".
**(c) Fully Asynchronous:**
* Explorer: Yellow "Rollout" blocks.
* Buffer: Blue blocks.
* Trainer: Green "Train" blocks interspersed with pink "Sync. weight (Checkpoint)" blocks.
* Data flows from Explorer to Buffer, then to Trainer.
* Synchronization occurs via checkpoints.
**(d) Multi-Explorer Asynchronous:**
* Explorer1 & Explorer2: Two Explorer lanes, each with yellow "Rollout" blocks.
* Buffer: Blue blocks.
* Trainer: Green "Train" blocks interspersed with red "Sync. weight (NCCL)" blocks.
* Data flows from both Explorers to the Buffer, then to the Trainer.
* Synchronization occurs via NCCL.
### Key Observations
* The Synchronous architecture requires waiting for experiences before training.
* The One-Step Off-Policy introduces a one-step offset and synchronization delay.
* The Fully Asynchronous architecture uses checkpoints for synchronization.
* The Multi-Explorer Asynchronous architecture utilizes multiple explorers and NCCL for synchronization.
* The complexity of synchronization increases as we move from Synchronous to Multi-Explorer Asynchronous.
* The color coding is consistent across all four diagrams.
### Interpretation
The diagram illustrates the evolution of asynchronous reinforcement learning architectures, highlighting different approaches to managing synchronization and data flow. The Synchronous approach is the simplest but can be inefficient due to waiting. The One-Step Off-Policy attempts to mitigate this with an offset, but still requires synchronization. The Fully Asynchronous and Multi-Explorer Asynchronous architectures aim to improve efficiency by reducing synchronization overhead, with the Multi-Explorer approach leveraging multiple explorers and faster NCCL synchronization. The choice of architecture depends on the specific application and the trade-off between synchronization overhead and training efficiency. The diagram effectively visualizes these trade-offs by showing the flow of data and the points at which synchronization occurs in each architecture. The use of color-coding makes it easy to understand the different phases of the learning process (Rollout, Train, Sync). The diagram suggests a progression towards more parallel and asynchronous approaches to improve the scalability and efficiency of reinforcement learning.