## Pie Charts: Error Analysis of Language Models
### Overview
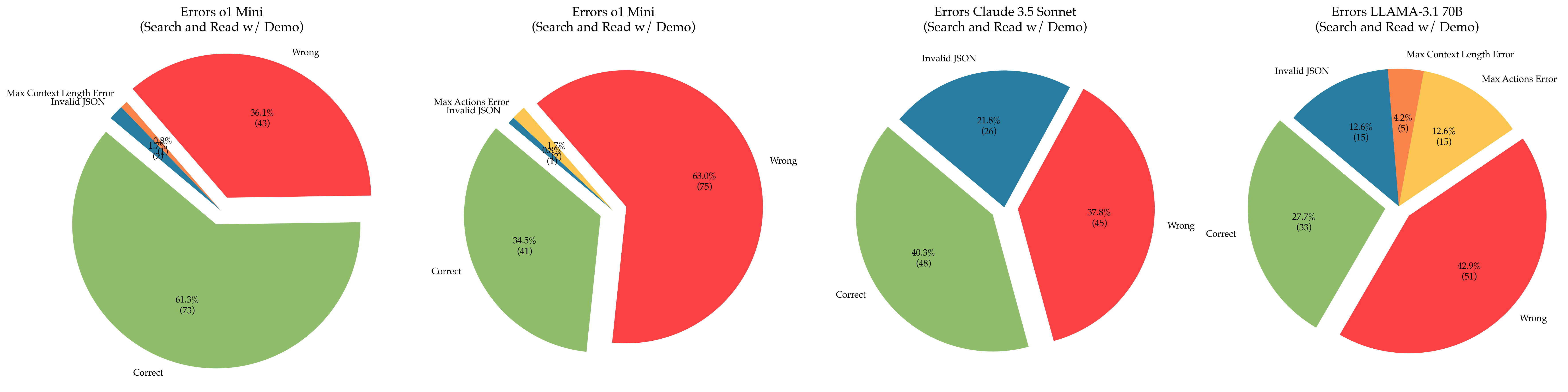
The image contains four pie charts, each representing the error distribution of a different language model during a "Search and Read w/ Demo" task. The models are o1 Mini (twice), Claude 3.5 Sonnet, and LLAMA-3.1 70B. The charts categorize errors into "Correct," "Wrong," "Invalid JSON," "Max Actions Error," and "Max Context Length Error." Each slice of the pie chart is labeled with a percentage and the number of occurrences in parentheses.
### Components/Axes
Each pie chart represents a language model. The slices represent error categories:
* **Correct:** Green
* **Wrong:** Red
* **Invalid JSON:** Blue
* **Max Actions Error:** Yellow
* **Max Context Length Error:** Orange
### Detailed Analysis
**Chart 1: Errors of o1 Mini (Search and Read w/ Demo)**
* **Correct:** 61.3% (73)
* **Wrong:** 36.1% (43)
* **Invalid JSON:** 1.7% (2)
* **Max Context Length Error:** 0.8% (1)
**Chart 2: Errors of o1 Mini (Search and Read w/ Demo)**
* **Correct:** 34.5% (41)
* **Wrong:** 63.0% (75)
* **Invalid JSON:** 0.8% (1)
* **Max Actions Error:** 1.7% (2)
**Chart 3: Errors of Claude 3.5 Sonnet (Search and Read w/ Demo)**
* **Correct:** 40.3% (48)
* **Wrong:** 37.8% (45)
* **Invalid JSON:** 21.8% (26)
**Chart 4: Errors of LLAMA-3.1 70B (Search and Read w/ Demo)**
* **Correct:** 27.7% (33)
* **Wrong:** 42.9% (51)
* **Invalid JSON:** 12.6% (15)
* **Max Actions Error:** 12.6% (15)
* **Max Context Length Error:** 4.2% (5)
### Key Observations
* The two charts for "o1 Mini" show different error distributions, suggesting variability in performance or different test conditions.
* Claude 3.5 Sonnet has a significant portion of errors categorized as "Invalid JSON" compared to the first "o1 Mini" chart.
* LLAMA-3.1 70B has a more diverse error distribution, with notable percentages for "Invalid JSON," "Max Actions Error," and "Max Context Length Error."
### Interpretation
The pie charts provide a comparative analysis of the error profiles of different language models during a specific task. The "o1 Mini" model shows inconsistent performance between the two trials. Claude 3.5 Sonnet struggles with JSON formatting, while LLAMA-3.1 70B exhibits a broader range of error types, indicating potential limitations in action execution and context handling. The data suggests that different models have different strengths and weaknesses, and their performance is influenced by the specific task and test conditions. Further investigation is needed to understand the underlying causes of these errors and to optimize the models for improved performance.