\n
## Pie Charts: Error Analysis of LLM Responses
### Overview
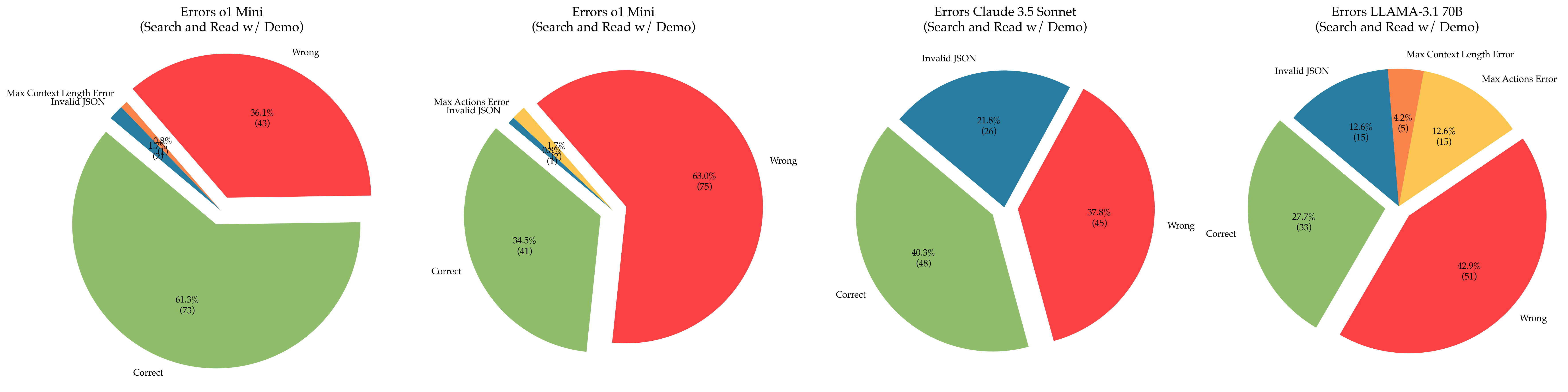
The image presents four pie charts, each representing the error distribution for a different Large Language Model (LLM) when performing a "Search and Read w/ Demo" task. The errors are categorized into "Correct", "Wrong", "Invalid JSON", and "Max Context Length Error" or "Max Actions Error". Each chart displays the percentage and count of each error type.
### Components/Axes
Each chart has the following components:
* **Title:** Indicates the LLM being analyzed (ol Mini, ol Mini, Claude 3.5 Sonnet, LLAMA-3.17B) and the task context ("Errors" + model name + " (Search and Read w/ Demo)").
* **Pie Slices:** Represent the proportion of each error category.
* **Labels:** Each slice is labeled with the error category and its percentage and count (e.g., "Correct (61.7%)", "Wrong (49)").
* **Color Coding:** Each error category is assigned a specific color:
* Correct: Green
* Wrong: Red
* Invalid JSON: Yellow
* Max Context Length Error/Max Actions Error: Orange
### Detailed Analysis or Content Details
**Chart 1: Errors ol Mini (Search and Read w/ Demo)**
* Correct: 61.7% (71)
* Wrong: 36.7% (42)
* Invalid JSON: 1.2% (1)
* Max Context Length Error: 0.4% (0)
**Chart 2: Errors ol Mini (Search and Read w/ Demo)**
* Correct: 34.5% (41)
* Wrong: 63.6% (73)
* Invalid JSON: 1.9% (2)
**Chart 3: Errors Claude 3.5 Sonnet (Search and Read w/ Demo)**
* Correct: 37.8% (45)
* Wrong: 40.3% (48)
* Invalid JSON: 21.9% (26)
**Chart 4: Errors LLAMA-3.17B (Search and Read w/ Demo)**
* Correct: 27.7% (33)
* Wrong: 42.9% (51)
* Invalid JSON: 12.6% (15)
* Max Actions Error: 12.6% (15)
* Max Context Length Error: 4.2% (5)
### Key Observations
* **ol Mini** shows the highest percentage of correct responses in the first chart (61.7%), but a significantly lower percentage in the second chart (34.5%).
* **Claude 3.5 Sonnet** has a substantial proportion of "Invalid JSON" errors (21.9%).
* **LLAMA-3.17B** exhibits a more distributed error profile, with significant percentages for "Wrong", "Invalid JSON", and "Max Actions Error".
* The "Max Context Length Error" is only present in the first and last charts, and is a small percentage of the total errors.
### Interpretation
The data suggests varying performance levels across the different LLMs on the "Search and Read w/ Demo" task. The significant difference in performance for "ol Mini" between the two charts could indicate variations in the input data or experimental setup. The high rate of "Invalid JSON" errors for "Claude 3.5 Sonnet" suggests a potential issue with its JSON formatting capabilities. "LLAMA-3.17B" appears to struggle with a broader range of errors, including generating incorrect responses, formatting errors, and exceeding context limits.
The presence of "Max Context Length Error" and "Max Actions Error" indicates that the models sometimes encounter limitations in handling the complexity or length of the input or the required actions. The charts provide a comparative overview of the error profiles, highlighting the strengths and weaknesses of each LLM in this specific task. Further investigation would be needed to understand the root causes of these errors and to improve the performance of the models.