# Technical Document Extraction: Llama 7B Performance Analysis
## 1. Header Information
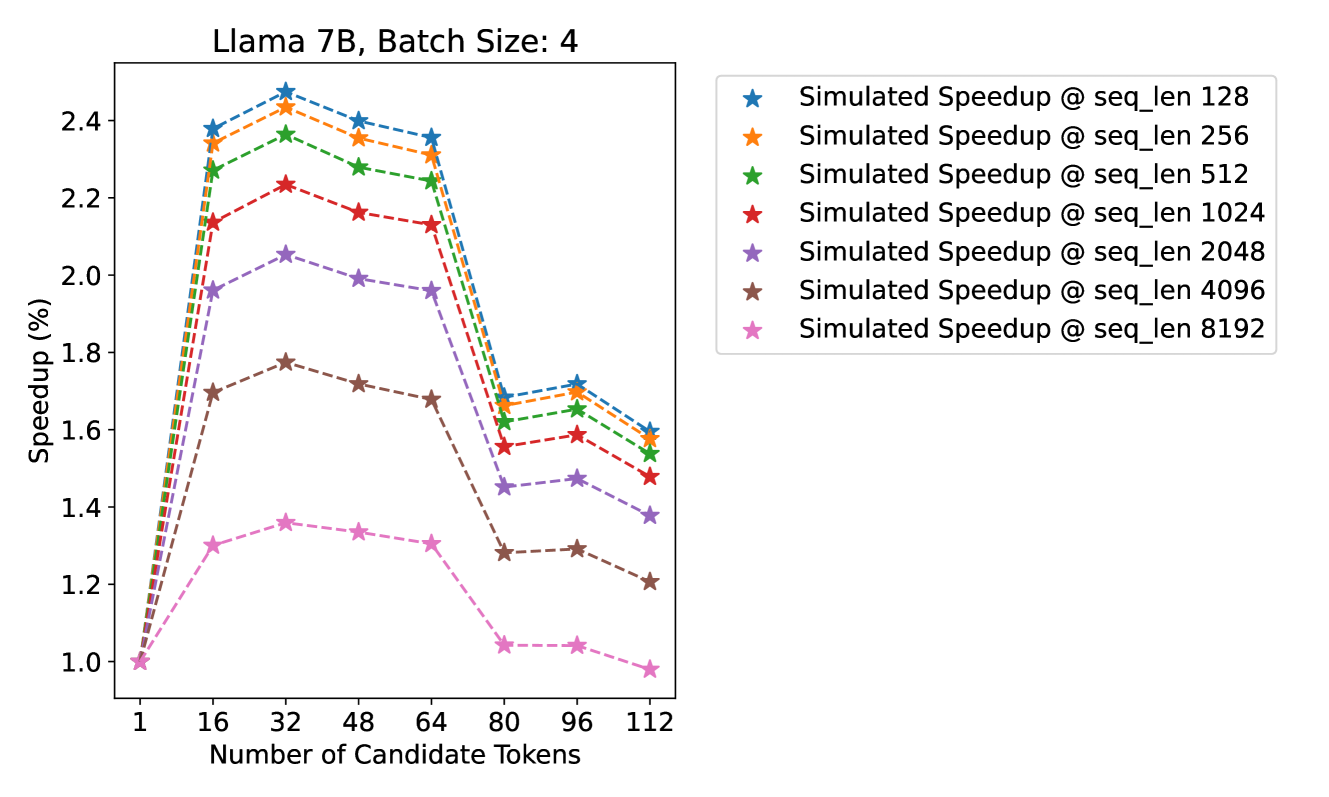
* **Title:** Llama 7B, Batch Size: 4
* **Primary Subject:** Simulated Speedup performance relative to the number of candidate tokens across various sequence lengths.
## 2. Component Isolation
### A. Axis Definitions
* **Y-Axis (Vertical):**
* **Label:** Speedup (%)
* **Scale:** Linear, ranging from 1.0 to 2.4 (increments of 0.2 marked).
* **X-Axis (Horizontal):**
* **Label:** Number of Candidate Tokens
* **Markers (Ticks):** 1, 16, 32, 48, 64, 80, 96, 112.
### B. Legend (Spatial Placement: Top Right [x=0.55 to 0.95, y=0.55 to 0.90])
The legend identifies seven data series, all represented by star markers connected by dashed lines.
1. **Blue Star:** Simulated Speedup @ seq_len 128
2. **Orange Star:** Simulated Speedup @ seq_len 256
3. **Green Star:** Simulated Speedup @ seq_len 512
4. **Red Star:** Simulated Speedup @ seq_len 1024
5. **Purple Star:** Simulated Speedup @ seq_len 2048
6. **Brown Star:** Simulated Speedup @ seq_len 4096
7. **Pink Star:** Simulated Speedup @ seq_len 8192
---
## 3. Trend Verification and Data Extraction
### General Visual Trend
All data series follow a consistent geometric pattern:
1. **Initial Surge:** A sharp upward slope from 1 to 16 candidate tokens.
2. **Peak Performance:** Reaching a maximum at 32 candidate tokens.
3. **Gradual Decline:** A slight downward slope between 32 and 64 tokens.
4. **Significant Drop:** A sharp vertical decline between 64 and 80 tokens.
5. **Secondary Peak/Plateau:** A minor recovery or stabilization between 80 and 96 tokens.
6. **Final Decline:** A downward slope toward 112 tokens.
7. **Inverse Correlation:** Speedup is inversely proportional to sequence length; shorter sequences (e.g., 128) consistently outperform longer sequences (e.g., 8192).
### Data Table (Estimated Values)
All series start at a baseline of **1.0 Speedup** at **1 Candidate Token**.
| Number of Candidate Tokens | seq_len 128 (Blue) | seq_len 256 (Orange) | seq_len 512 (Green) | seq_len 1024 (Red) | seq_len 2048 (Purple) | seq_len 4096 (Brown) | seq_len 8192 (Pink) |
| :--- | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
| **1** | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 |
| **16** | ~2.38 | ~2.34 | ~2.27 | ~2.14 | ~1.96 | ~1.70 | ~1.30 |
| **32 (Peak)** | **~2.48** | **~2.44** | **~2.37** | **~2.24** | **~2.06** | **~1.78** | **~1.36** |
| **48** | ~2.40 | ~2.36 | ~2.28 | ~2.16 | ~1.99 | ~1.72 | ~1.34 |
| **64** | ~2.36 | ~2.32 | ~2.24 | ~2.13 | ~1.96 | ~1.68 | ~1.31 |
| **80 (Drop)** | ~1.68 | ~1.66 | ~1.62 | ~1.56 | ~1.45 | ~1.28 | ~1.04 |
| **96** | ~1.72 | ~1.70 | ~1.66 | ~1.59 | ~1.48 | ~1.29 | ~1.04 |
| **112** | ~1.60 | ~1.58 | ~1.54 | ~1.48 | ~1.38 | ~1.21 | ~0.98 |
---
## 4. Key Observations
* **Optimal Configuration:** For all sequence lengths, the "Number of Candidate Tokens" value of **32** yields the highest speedup.
* **Performance Ceiling:** The maximum speedup achieved is approximately **2.48x (248%)** for the shortest sequence length (128) at 32 candidate tokens.
* **Efficiency Threshold:** There is a critical performance "cliff" after 64 candidate tokens. The speedup drops by approximately 0.6x to 0.7x across most series when moving from 64 to 80 tokens, suggesting a hardware or architectural bottleneck (likely memory or cache related) triggered at that specific token count.
* **Long Sequence Penalty:** At a sequence length of 8192, the speedup barely stays above 1.0 and actually dips slightly below the baseline (to ~0.98) at 112 candidate tokens, indicating that the overhead of candidate tokens outweighs the benefits for very long sequences at high token counts.