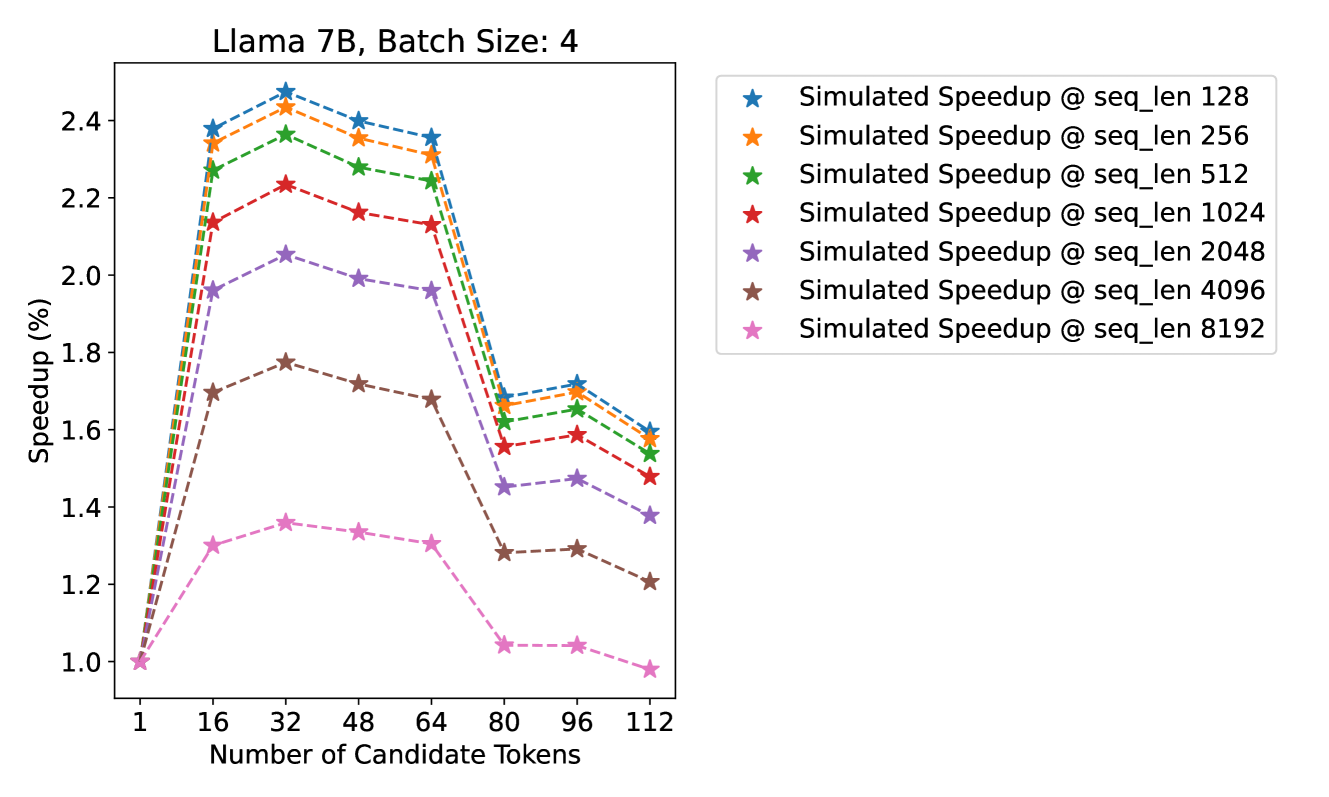
# Technical Analysis of Speedup Performance for Llama 7B Model
## Chart Title
**Llama 7B, Batch Size: 4**
## Axes Labels
- **X-Axis**: Number of Candidate Tokens (1, 16, 32, 48, 64, 80, 96, 112)
- **Y-Axis**: Speedup (%) (1.0, 1.2, 1.4, 1.6, 1.8, 2.0, 2.2, 2.4, 2.6)
## Legend Entries
| Color/Symbol | Label |
|--------------|-------|
| Blue Star | Simulated Speedup @ seq_len 128 |
| Orange Star | Simulated Speedup @ seq_len 256 |
| Green Star | Simulated Speedup @ seq_len 512 |
| Red Star | Simulated Speedup @ seq_len 1024 |
| Purple Star | Simulated Speedup @ seq_len 2048 |
| Brown Star | Simulated Speedup @ seq_len 4096 |
| Pink Star | Simulated Speedup @ seq_len 8192 |
## Key Trends
1. **Speedup Peaks**:
- All sequence lengths show maximum speedup at **32 candidate tokens** (~2.4-2.5%).
- Exception: `seq_len 8192` peaks at **16 tokens** (~2.3%).
2. **Performance Decline**:
- Speedup decreases sharply after 32 tokens for most sequence lengths.
- `seq_len 8192` shows gradual decline after 16 tokens.
3. **Relative Performance**:
- `seq_len 128` (blue) maintains highest speedup across all token counts.
- `seq_len 8192` (pink) consistently exhibits lowest speedup.
## Data Points
| Token Count | seq_len 128 | seq_len 256 | seq_len 512 | seq_len 1024 | seq_len 2048 | seq_len 4096 | seq_len 8192 |
|-------------|-------------|-------------|-------------|--------------|--------------|--------------|--------------|
| 1 | 2.4% | 2.3% | 2.3% | 2.1% | 1.9% | 1.7% | 1.0% |
| 16 | 2.5% | 2.4% | 2.3% | 2.2% | 2.0% | 1.7% | 1.3% |
| 32 | 2.5% | 2.4% | 2.3% | 2.2% | 2.1% | 1.7% | 1.4% |
| 48 | 2.4% | 2.3% | 2.2% | 2.1% | 1.9% | 1.6% | 1.3% |
| 64 | 2.3% | 2.2% | 2.1% | 2.0% | 1.8% | 1.5% | 1.3% |
| 80 | 1.7% | 1.6% | 1.6% | 1.5% | 1.4% | 1.3% | 1.0% |
| 96 | 1.7% | 1.6% | 1.6% | 1.5% | 1.4% | 1.3% | 1.0% |
| 112 | 1.6% | 1.5% | 1.5% | 1.4% | 1.3% | 1.2% | 0.9% |
## Technical Observations
- **Batch Size Impact**: All simulations use batch size = 4.
- **Sequence Length Correlation**: Longer sequence lengths (e.g., 8192) show reduced speedup efficiency.
- **Optimal Token Range**: 16-32 tokens provide best performance for most configurations.