TECHNICAL ASSET FINGERPRINT
ef50404765727bdb9605a2a1
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
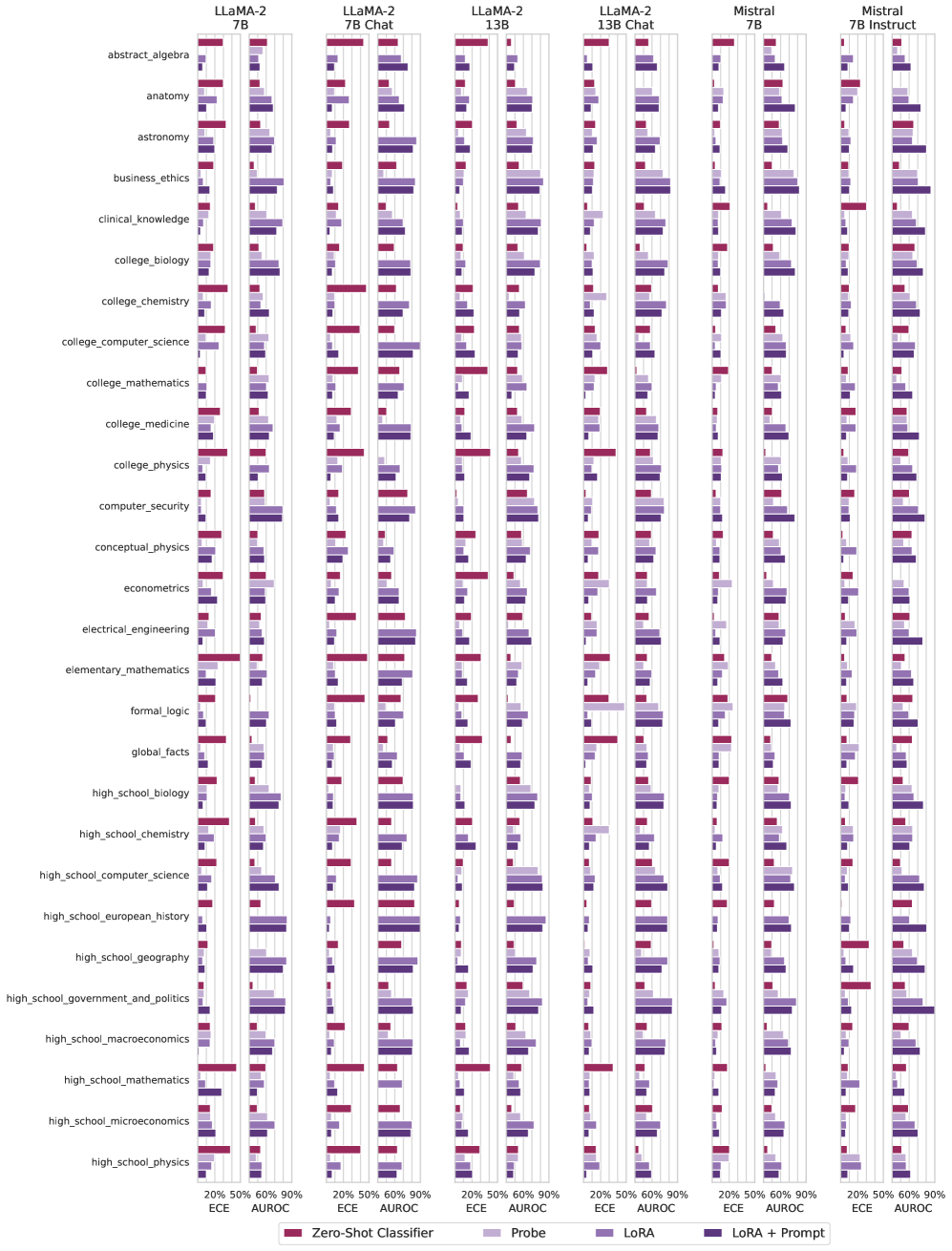
## [Grouped Bar Chart]: Performance of Language Models on Academic Subjects Using Different Tuning Methods
### Overview
This image is a complex, multi-panel grouped bar chart comparing the performance of six different large language models (LLMs) across 25 academic subjects. Performance is measured using two metrics (ECE and AUROC) for four different model tuning or prompting methods. The chart is designed to facilitate comparison both across models for a given subject and across subjects for a given model.
### Components/Axes
* **Main Structure:** The chart is divided into six vertical panels (columns), each dedicated to a specific model.
* **Model Panels (Top Labels, Left to Right):**
1. LLaMA-2 7B
2. LLaMA-2 7B Chat
3. LLaMA-2 13B
4. LLaMA-2 13B Chat
5. Mistral 7B
6. Mistral 7B Instruct
* **Y-Axis (Left Side):** Lists 25 academic subjects. From top to bottom:
* abstract_algebra, anatomy, astronomy, business_ethics, clinical_knowledge, college_biology, college_chemistry, college_computer_science, college_mathematics, college_medicine, college_physics, computer_security, conceptual_physics, econometrics, electrical_engineering, elementary_mathematics, formal_logic, global_facts, high_school_biology, high_school_chemistry, high_school_computer_science, high_school_european_history, high_school_geography, high_school_government_and_politics, high_school_macroeconomics, high_school_mathematics, high_school_microeconomics, high_school_physics.
* **X-Axis (Bottom of Each Panel):** Each model panel has its own x-axis with two sections:
* **Left Section:** Labeled "ECE" (Expected Calibration Error). Scale markers: 20%, 50%, 90%. Lower values are better for ECE.
* **Right Section:** Labeled "AUROC" (Area Under the Receiver Operating Characteristic Curve). Scale markers: 20%, 50%, 90%. Higher values are better for AUROC.
* **Legend (Bottom Center):** Defines the four colored bars present for each subject within each model panel.
* **Red/Maroon:** Zero-Shot Classifier
* **Light Purple/Lavender:** Probe
* **Medium Purple:** LoRA
* **Dark Purple/Indigo:** LoRA + Prompt
### Detailed Analysis
The chart presents a dense matrix of data. For each of the 25 subjects in each of the 6 models, four bars are shown, grouped by the ECE and AUROC metrics.
**General Trends Across Models:**
1. **Method Performance Hierarchy:** For the AUROC metric (right side of each panel), the "LoRA + Prompt" (dark purple) bar is consistently the longest (highest value) across nearly all subjects and models. "LoRA" (medium purple) is typically second, followed by "Probe" (light purple). The "Zero-Shot Classifier" (red) generally shows the lowest AUROC performance.
2. **Model Size/Chat Effect:** Comparing LLaMA-2 7B to 13B, and base to Chat variants, the Chat-tuned models (LLaMA-2 7B Chat, LLaMA-2 13B Chat) often show improved AUROC scores, particularly for the "LoRA + Prompt" method, compared to their base counterparts.
3. **Mistral vs. LLaMA:** The Mistral models (7B and 7B Instruct) display performance patterns broadly similar to the LLaMA-2 models of comparable size, with "LoRA + Prompt" being dominant. The Mistral 7B Instruct model shows particularly strong AUROC scores for "LoRA + Prompt" in several subjects.
4. **ECE Metric:** The ECE values (left side of each panel) are generally low (bars are short) across the board, indicating relatively well-calibrated models. There is less dramatic variation between methods for ECE compared to AUROC. The "Zero-Shot Classifier" sometimes shows slightly higher (worse) ECE.
**Subject-Specific Observations (Selected Examples):**
* **high_school_government_and_politics:** In the Mistral 7B Instruct panel, the "Zero-Shot Classifier" (red) bar for AUROC is exceptionally long, reaching near 90%, which is an outlier compared to its performance in other subjects and compared to other models.
* **college_computer_science:** Across most models, the AUROC scores for all methods are relatively high, suggesting this is a subject where models perform well.
* **formal_logic:** This subject appears challenging. The AUROC bars, even for "LoRA + Prompt," are shorter on average compared to many other subjects across all models.
* **abstract_algebra:** Shows significant variation in "Zero-Shot Classifier" (red) AUROC performance between models, from very low in LLaMA-2 7B to moderately high in Mistral 7B Instruct.
### Key Observations
1. **Dominant Method:** The "LoRA + Prompt" tuning method is the clear top performer for accuracy (AUROC) across virtually all subjects and models tested.
2. **Consistent Hierarchy:** The performance order of the four methods (LoRA + Prompt > LoRA > Probe > Zero-Shot Classifier) is remarkably consistent for the AUROC metric.
3. **Model Robustness:** The Chat-tuned and Instruct-tuned variants of the models generally provide a performance boost over their base counterparts when using advanced tuning methods like LoRA + Prompt.
4. **Subject Difficulty:** Subjects like `formal_logic` and `econometrics` appear consistently more challenging (lower AUROC scores) than subjects like `college_computer_science` or `high_school_biology`.
5. **Notable Outlier:** The `Zero-Shot Classifier` performance on `high_school_government_and_politics` with the `Mistral 7B Instruct` model is a significant positive outlier for that specific method.
### Interpretation
This chart provides a comprehensive benchmark for evaluating how different adaptation techniques (zero-shot, probing, LoRA, and LoRA with prompting) affect the performance of open-weight LLMs on a wide range of academic knowledge tasks.
The data strongly suggests that **combining parameter-efficient fine-tuning (LoRA) with engineered prompts yields the most accurate and reliable results** for knowledge-intensive tasks. The consistent hierarchy implies that more sophisticated adaptation methods unlock greater latent knowledge from the base models.
The variation across subjects indicates that **model knowledge is not uniform**; some domains (e.g., computer science, biology) are better represented in the models' training data or are more amenable to the evaluation format than others (e.g., formal logic, advanced economics).
The relative stability of the ECE metric suggests that while these tuning methods significantly improve accuracy (AUROC), they do not drastically harm the models' calibration (their ability to estimate their own confidence correctly). This is important for trustworthy deployment.
From a practical standpoint, a researcher or engineer looking to maximize performance on a specific academic domain would likely choose the "LoRA + Prompt" approach. The chart also helps identify which models (e.g., Mistral 7B Instruct, LLaMA-2 13B Chat) are strongest overall and which subjects might require additional data or specialized techniques.
DECODING INTELLIGENCE...