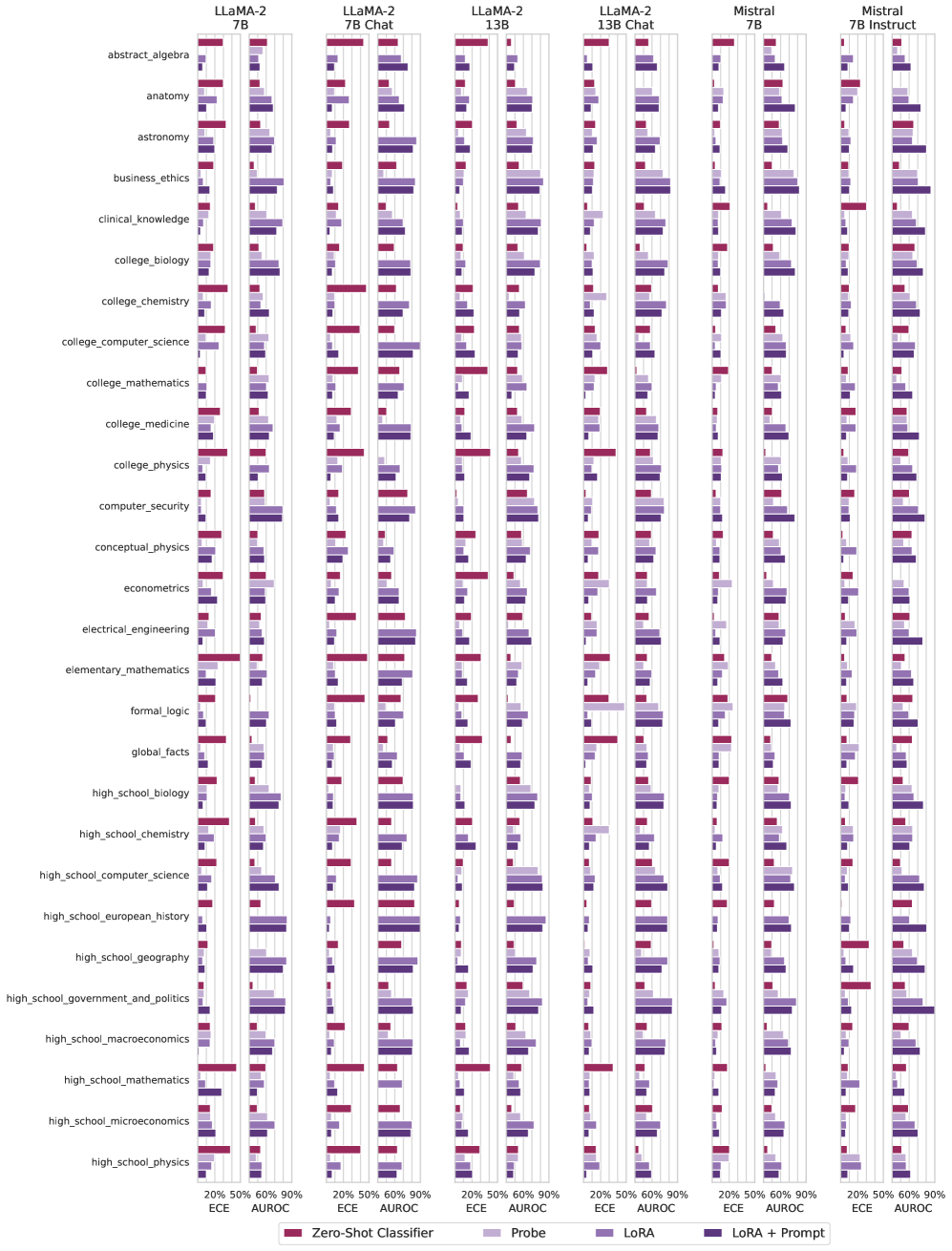
## Bar Chart: Model Performance Comparison Across Subjects
### Overview
The chart compares the performance of multiple AI models (LLaMA-2 7B, LLaMA-2 13B, LLaMA-2 13B Chat, Mistral 7B, Mistral 7B Instruct) across 25 academic subjects using two evaluation metrics: Expected Calibration Error (ECE) and Area Under the Receiver Operating Characteristic curve (AUROC). Performance is visualized as grouped bars for each subject, with color-coded models and percentage-based axes.
### Components/Axes
- **Y-Axis**: Subjects (e.g., `abstract_algebra`, `astronomy`, `high_school_physics`), listed alphabetically.
- **X-Axes**:
- Left: ECE (20%, 50%, 60%, 90% markers).
- Right: AUROC (20%, 50%, 60%, 90% markers).
- **Legend**:
- Red: Zero-Shot Classifier
- Light Purple: Probe
- Dark Purple: LoRA
- Dark Blue: LoRA + Prompt
- Gray: LLaMA-2 7B
- Dark Red: LLaMA-2 13B
- Light Blue: LLaMA-2 13B Chat
- Dark Green: Mistral 7B
- Light Gray: Mistral 7B Instruct
### Detailed Analysis
- **ECE Trends**:
- Mistral 7B Instruct (light gray) consistently shows the lowest ECE (20-30%) across most subjects.
- LLaMA-2 13B (dark red) and Mistral 7B (dark green) often cluster around 50-60% ECE.
- Larger models (LLaMA-2 13B, Mistral 7B) generally outperform smaller models (LLaMA-2 7B, Mistral 7B) in ECE for subjects like `college_chemistry` and `high_school_mathematics`.
- **AUROC Trends**:
- LLaMA-2 13B Chat (light blue) and Mistral 7B Instruct (light gray) dominate AUROC (70-90%) in subjects like `college_biology` and `high_school_geography`.
- LLaMA-2 7B (gray) and Mistral 7B (dark green) show lower AUROC (40-60%) in `astronomy` and `econometrics`.
- AUROC values are consistently higher than ECE across all models and subjects.
### Key Observations
1. **Model Size vs. Performance**:
- Larger models (LLaMA-2 13B, Mistral 7B) generally achieve higher AUROC but not always lower ECE.
- Instruction-tuned models (LLaMA-2 13B Chat, Mistral 7B Instruct) excel in both metrics for specific subjects.
2. **Subject-Specific Variability**:
- `high_school_physics` and `college_computer_science` show the widest performance gaps between models.
- `business_ethics` and `global_facts` have tightly clustered AUROC values across models.
3. **Anomalies**:
- Mistral 7B Instruct (light gray) underperforms in AUROC for `high_school_microeconomics` compared to other models.
- LLaMA-2 7B (gray) has disproportionately high ECE in `high_school_government_and_politics`.
### Interpretation
The chart reveals that model architecture and training methodology significantly influence performance across academic domains. Instruction-tuned variants (e.g., LLaMA-2 13B Chat, Mistral 7B Instruct) demonstrate superior calibration (lower ECE) and generalization (higher AUROC) in specialized subjects like `college_chemistry` and `high_school_geography`. However, smaller models (LLaMA-2 7B, Mistral 7B) struggle with calibration in politically sensitive topics (`high_school_government_and_politics`), suggesting domain-specific knowledge gaps. The consistent AUROC superiority of larger models implies that scale improves generalization, but instruction tuning is critical for real-world applicability. The anomaly in `high_school_microeconomics` highlights potential weaknesses in economic reasoning across models.