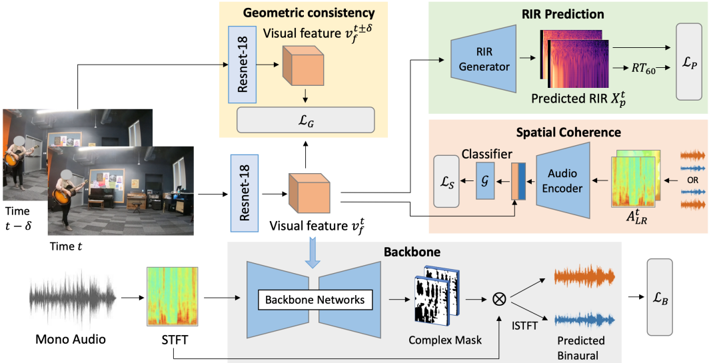
## System Architecture Diagram: Audio-Visual Processing Pipeline
### Overview
The diagram illustrates a multi-modal deep learning system for audio-visual processing, integrating geometric consistency, RIR (Room Impulse Response) prediction, and spatial coherence. It processes mono audio and visual inputs over time to predict binaural audio and spatial properties.
### Components/Axes
1. **Input Streams**:
- **Mono Audio**: Raw audio waveform (time-domain).
- **Visual Input**: Frames at time `t` and `t-δ` (temporal offset).
2. **Processing Blocks**:
- **STFT**: Short-Time Fourier Transform (audio preprocessing).
- **ResNet-18**: Visual feature extraction (`v_f^t`, `v_f^{t-δ}`).
- **Backbone Networks**: Audio-visual feature fusion.
- **Complex Mask**: Audio-visual alignment mechanism.
- **ISTFT**: Inverse STFT (audio reconstruction).
- **RIR Generator**: Predicts room impulse responses (`X_p^t`).
- **Classifier/Audio Encoder**: Spatial coherence module.
3. **Loss Functions**:
- `L_G`: Geometric consistency loss.
- `L_P`: RIR prediction loss.
- `L_S`: Spatial coherence loss.
- `L_B`: Backbone network loss.
### Detailed Analysis
- **Geometric Consistency**:
- Visual features (`v_f^t`, `v_f^{t-δ}`) are extracted via ResNet-18 and used to enforce temporal alignment (`L_G`).
- **RIR Prediction**:
- The RIR Generator uses visual features to predict room impulse responses (`X_p^t`), optimized via `L_P`.
- **Spatial Coherence**:
- A classifier and audio encoder (`A_LR^t`) ensure audio matches visual context, with loss `L_S`.
- **Backbone Network**:
- Fuses audio (STFT) and visual features via a complex mask, with ISTFT for binaural audio prediction (`L_B`).
### Key Observations
- **Temporal Alignment**: The use of `t` and `t-δ` indicates explicit modeling of temporal relationships in visual data.
- **Modular Design**: Separate modules for RIR prediction, spatial coherence, and geometric consistency suggest modular optimization.
- **Loss Function Diversity**: Four distinct losses (`L_G`, `L_P`, `L_S`, `L_B`) highlight multi-objective training.
### Interpretation
This architecture is designed for **spatially aware audio synthesis**, likely for applications like virtual reality or augmented reality. The integration of RIR prediction ensures audio realism by modeling room acoustics from visual cues. The backbone network’s fusion of audio-visual features via a complex mask suggests attention to cross-modal alignment. The use of ResNet-18 for visual features and ISTFT for audio reconstruction indicates a focus on temporal and spatial fidelity.
**Notable Design Choices**:
- **Time Offsets (`t-δ`)**: Explicitly model temporal consistency in visual inputs.
- **Complex Mask**: Likely enables phase-aware audio-visual alignment.
- **RIR Prediction**: Critical for immersive audio experiences, as RIRs define how sound propagates in a space.
**Limitations**:
- No explicit handling of occlusions or dynamic scenes (e.g., moving objects).
- Assumes static camera positions for visual inputs.