## Bar Chart: CogGRAG Performance on Question Answering Datasets
### Overview
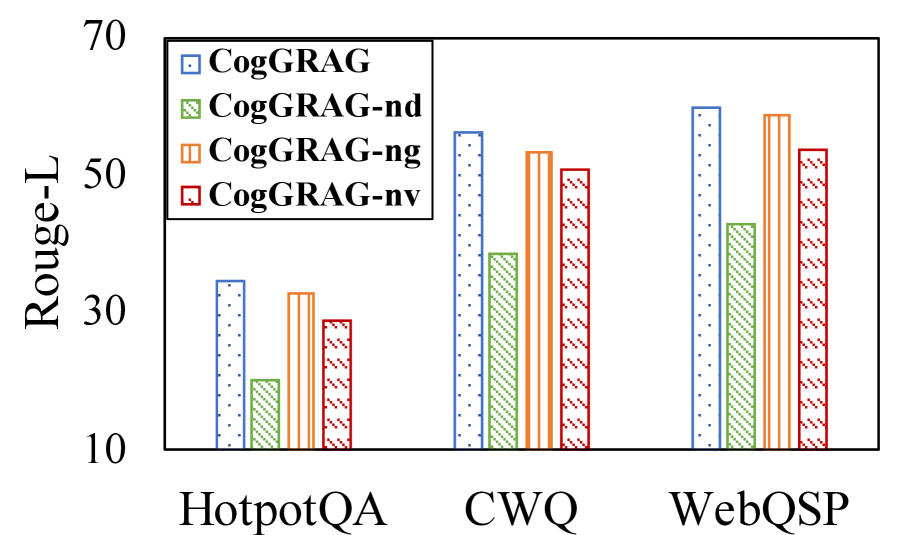
The image is a bar chart comparing the performance of different CogGRAG models on three question answering datasets: HotpotQA, CWQ, and WebQSP. The y-axis represents the Rouge-L score, a measure of text similarity, and the x-axis represents the datasets. The chart displays the Rouge-L scores for four CogGRAG variants: CogGRAG, CogGRAG-nd, CogGRAG-ng, and CogGRAG-nv.
### Components/Axes
* **Y-axis:** Rouge-L, with scale markers at 10, 30, 50, and 70.
* **X-axis:** Datasets: HotpotQA, CWQ, WebQSP.
* **Legend (top-left):**
* Blue: CogGRAG
* Green: CogGRAG-nd
* Orange: CogGRAG-ng
* Red: CogGRAG-nv
### Detailed Analysis
The chart presents the Rouge-L scores for each CogGRAG variant across the three datasets.
* **HotpotQA:**
* CogGRAG (blue): Approximately 34
* CogGRAG-nd (green): Approximately 20
* CogGRAG-ng (orange): Approximately 32
* CogGRAG-nv (red): Approximately 29
* **CWQ:**
* CogGRAG (blue): Approximately 57
* CogGRAG-nd (green): Approximately 38
* CogGRAG-ng (orange): Approximately 54
* CogGRAG-nv (red): Approximately 51
* **WebQSP:**
* CogGRAG (blue): Approximately 60
* CogGRAG-nd (green): Approximately 42
* CogGRAG-ng (orange): Approximately 59
* CogGRAG-nv (red): Approximately 54
### Key Observations
* CogGRAG (blue) generally achieves the highest Rouge-L scores across all datasets.
* CogGRAG-nd (green) consistently shows the lowest Rouge-L scores compared to other variants.
* The performance difference between CogGRAG-ng (orange) and CogGRAG-nv (red) is relatively small, with CogGRAG-ng slightly outperforming CogGRAG-nv.
* All CogGRAG variants perform better on CWQ and WebQSP compared to HotpotQA.
### Interpretation
The bar chart illustrates the performance of different CogGRAG models on various question answering datasets, as measured by the Rouge-L metric. The results suggest that the base CogGRAG model performs the best overall. The "nd" variant consistently underperforms, indicating that the specific modification it incorporates negatively impacts performance. The "ng" and "nv" variants show similar performance, suggesting that their respective modifications have a comparable effect on the model's ability to generate text similar to the ground truth. The higher scores on CWQ and WebQSP compared to HotpotQA may indicate that CogGRAG models are better suited for these types of question answering tasks, or that these datasets are inherently easier.