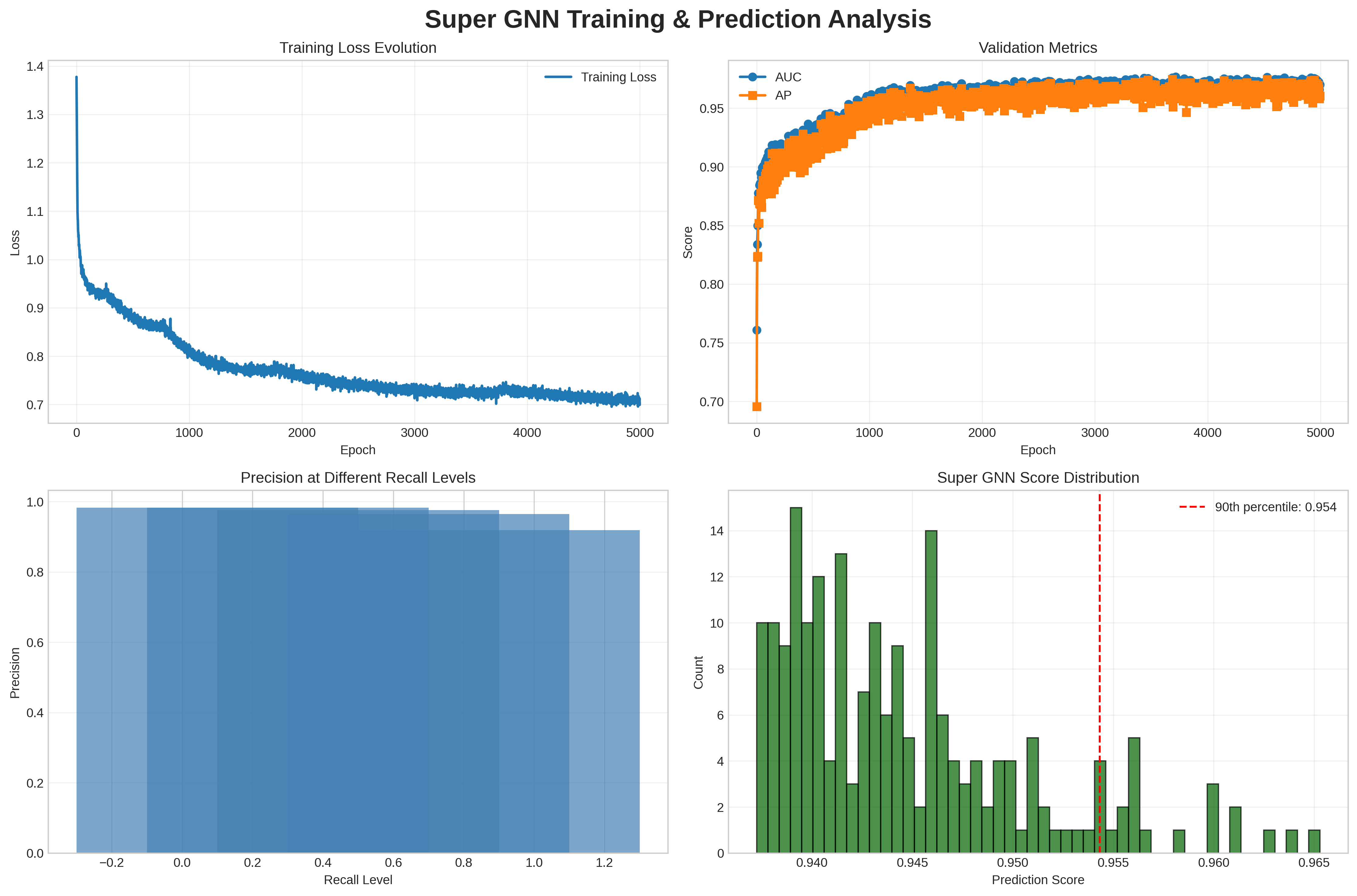
## Super GNN Training & Prediction Analysis
### Overview
This is a 2x2 composite figure analyzing the training, validation, and predictive performance of a "Super GNN" (Graph Neural Network) model. It includes four subplots: training loss evolution, validation metrics (AUC/AP), precision-recall performance, and prediction score distribution.
---
### Components/Axes & Detailed Analysis
#### 1. Top-Left: Training Loss Evolution
- **Type**: Line plot
- **Axes**:
- X-axis: `Epoch` (range: 0 to 5000, linear scale)
- Y-axis: `Loss` (range: 0.7 to 1.4, linear scale)
- **Data Series**: Single blue line labeled `Training Loss`
- **Trend & Values**:
- Starts at ~1.38 (epoch 0), drops sharply to ~0.95 by epoch 100.
- Gradually decreases with minor fluctuations, ending at ~0.7 at epoch 5000.
- The curve shows classic training convergence: rapid initial loss reduction, followed by slow, steady improvement as training progresses.
#### 2. Top-Right: Validation Metrics
- **Type**: Line plot with markers
- **Axes**:
- X-axis: `Epoch` (range: 0 to 5000, linear scale)
- Y-axis: `Score` (range: 0.70 to 0.97, linear scale)
- **Legend**:
- `AUC` (blue circle markers)
- `AP` (orange square markers)
- **Trend & Values**:
- **AUC**: Starts at ~0.76 (epoch 0), rises rapidly to ~0.92 by epoch 500, then plateaus at ~0.96-0.97 from epoch 1000 onwards, with minor fluctuations.
- **AP**: Starts at ~0.70 (epoch 0), rises to ~0.85 by epoch 500, then plateaus at ~0.94-0.96 from epoch 1000 onwards, consistently slightly below AUC.
- Both metrics show rapid early improvement, then stabilize, indicating the model's validation performance converges after ~1000 epochs.
#### 3. Bottom-Left: Precision at Different Recall Levels
- **Type**: Filled area precision-recall curve
- **Axes**:
- X-axis: `Recall Level` (range: -0.2 to 1.2, linear scale)
- Y-axis: `Precision` (range: 0.0 to 1.0, linear scale)
- **Data**:
- Precision remains near 1.0 (≈0.98-1.0) for recall levels from -0.2 up to ~0.8.
- Precision slightly decreases to ~0.95 at the maximum recall level (1.2).
- The curve demonstrates the model maintains near-perfect precision across almost all recall levels, with only a small drop at the highest recall values.
#### 4. Bottom-Right: Super GNN Score Distribution
- **Type**: Histogram
- **Axes**:
- X-axis: `Prediction Score` (range: 0.940 to 0.965, linear scale)
- Y-axis: `Count` (range: 0 to 14, linear scale)
- **Legend**: Red dashed line labeled `90th percentile: 0.954`
- **Data**:
- The histogram is right-skewed: the highest count (14) occurs at ~0.942, with counts decreasing as prediction scores increase.
- The 90th percentile marker at 0.954 indicates 90% of prediction scores are ≤0.954, and 10% of scores are above this value.
- Most scores cluster between 0.940-0.955, with only a small tail of scores above 0.955.
---
### Key Observations
1. Training loss converges steadily, with no signs of divergence or overfitting.
2. Validation metrics (AUC, AP) stabilize at high values (~0.96 for AUC, ~0.95 for AP), indicating strong generalization to unseen data.
3. The precision-recall curve shows near-perfect precision across nearly all recall levels, a strong indicator of classification performance.
4. Prediction scores are concentrated in the high-confidence range (0.94-0.955), with 90% of scores ≤0.954.
---
### Interpretation
This set of plots confirms the Super GNN model performs exceptionally well on its target task:
1. **Effective Learning**: The training loss curve shows the model learns efficiently, with rapid initial improvement and steady convergence, indicating the model architecture and training process are well-suited to the task.
2. **Strong Generalization**: High, stable validation AUC and AP scores prove the model does not overfit, and maintains strong performance on unseen data.
3. **Excellent Classification Tradeoff**: The precision-recall curve demonstrates the model can retrieve nearly all positive samples (high recall) while maintaining near-perfect precision, meaning it rarely misclassifies negative samples as positive.
4. **High-Confidence Predictions**: The score distribution shows most predictions are high-confidence, with only a small fraction of extreme high scores, indicating the model is consistent and reliable in its outputs.