## Line Chart: LM Loss vs. Position for Different Attention Mechanisms
### Overview
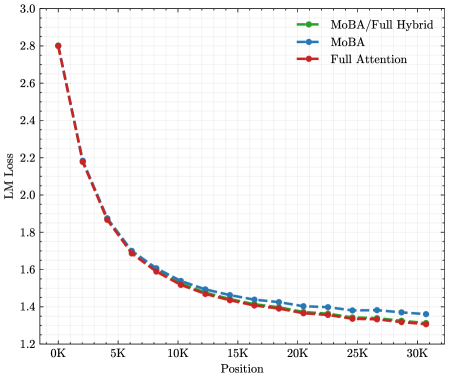
The image is a line chart comparing the Language Model (LM) Loss against Position (in thousands) for three different attention mechanisms: MoBA/Full Hybrid, MoBA, and Full Attention. The chart shows how the LM Loss decreases as the position increases for each mechanism.
### Components/Axes
* **Title:** There is no explicit title on the chart.
* **X-axis:**
* Label: "Position"
* Units: Thousands (K)
* Scale: 0K, 5K, 10K, 15K, 20K, 25K, 30K
* **Y-axis:**
* Label: "LM Loss"
* Scale: 1.2, 1.4, 1.6, 1.8, 2.0, 2.2, 2.4, 2.6, 2.8, 3.0
* **Legend:** Located in the top-right corner of the chart.
* Green: MoBA/Full Hybrid
* Blue: MoBA
* Red: Full Attention
### Detailed Analysis
* **MoBA/Full Hybrid (Green):** The green line represents the MoBA/Full Hybrid attention mechanism. The line starts at approximately 2.8 and decreases to around 1.35.
* Position 0K: ~2.8
* Position 5K: ~1.85
* Position 10K: ~1.55
* Position 15K: ~1.45
* Position 20K: ~1.4
* Position 25K: ~1.35
* Position 30K: ~1.35
* **MoBA (Blue):** The blue line represents the MoBA attention mechanism. The line starts at approximately 2.8 and decreases to around 1.38.
* Position 0K: ~2.8
* Position 5K: ~1.85
* Position 10K: ~1.55
* Position 15K: ~1.45
* Position 20K: ~1.42
* Position 25K: ~1.4
* Position 30K: ~1.38
* **Full Attention (Red):** The red dashed line represents the Full Attention mechanism. The line starts at approximately 2.8 and decreases to around 1.32.
* Position 0K: ~2.8
* Position 5K: ~2.2
* Position 10K: ~1.6
* Position 15K: ~1.45
* Position 20K: ~1.4
* Position 25K: ~1.35
* Position 30K: ~1.32
### Key Observations
* All three attention mechanisms show a decrease in LM Loss as the position increases.
* The Full Attention mechanism (red line) has a steeper initial decline in LM Loss compared to the other two.
* At higher positions (20K-30K), the LM Loss values for all three mechanisms converge, with Full Attention showing a slightly lower loss.
* The MoBA and MoBA/Full Hybrid lines are very close to each other.
### Interpretation
The chart suggests that all three attention mechanisms improve in performance (lower LM Loss) as the position increases. The Full Attention mechanism initially reduces the loss more rapidly, but the performance difference between the three mechanisms becomes smaller at higher positions. This could indicate that Full Attention is more effective at capturing initial dependencies, but the benefits diminish as the model processes more data. The convergence of the lines at higher positions suggests that the choice of attention mechanism becomes less critical as the model learns. The MoBA and MoBA/Full Hybrid mechanisms perform similarly, suggesting that the hybrid approach does not offer a significant advantage over MoBA alone in this context.