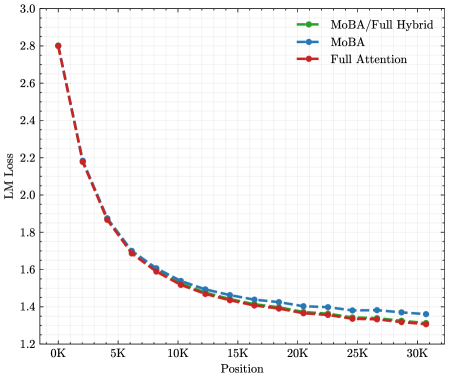
## Line Chart: LM Loss vs. Position for Three Attention Mechanisms
### Overview
The image is a line chart comparing the performance of three different attention mechanisms—MoBA/Full Hybrid, MoBA, and Full Attention—by plotting their Language Model (LM) Loss against sequence Position. The chart demonstrates how the loss decreases for all three methods as the position index increases, with all three following a very similar, steeply decaying curve.
### Components/Axes
* **Chart Type:** Line chart with markers.
* **X-Axis:**
* **Title:** `Position`
* **Scale:** Linear, from `0K` to `30K`.
* **Major Tick Marks:** `0K`, `5K`, `10K`, `15K`, `20K`, `25K`, `30K`.
* **Y-Axis:**
* **Title:** `LM Loss`
* **Scale:** Linear, from `1.2` to `3.0`.
* **Major Tick Marks:** `1.2`, `1.4`, `1.6`, `1.8`, `2.0`, `2.2`, `2.4`, `2.6`, `2.8`, `3.0`.
* **Legend:** Located in the top-right corner of the plot area.
* **Green line with circle markers:** `MoBA/Full Hybrid`
* **Blue line with diamond markers:** `MoBA`
* **Red dashed line with square markers:** `Full Attention`
* **Background:** A light gray grid is present for easier value estimation.
### Detailed Analysis
**Trend Verification:** All three data series exhibit the same fundamental trend: a sharp, convex decay in LM Loss as Position increases. The loss is highest at the beginning of the sequence (Position 0K) and decreases rapidly, with the rate of decrease slowing significantly after approximately Position 10K.
**Data Point Extraction (Approximate Values):**
* **At Position 0K:** All three lines start at approximately the same point, with an LM Loss of ~`2.8`.
* **At Position 5K:** Loss has dropped sharply to ~`1.85` for all series.
* **At Position 10K:** Loss is approximately `1.55`.
* **At Position 15K:** Loss is approximately `1.45`.
* **At Position 20K:** Loss is approximately `1.38`.
* **At Position 25K:** Loss is approximately `1.34`.
* **At Position 30K:** Loss is approximately `1.32`.
**Cross-Referencing Legend with Lines:**
* The **green line (MoBA/Full Hybrid)** consistently appears as the lowest line on the chart across all positions, though the difference is very small.
* The **blue line (MoBA)** is generally in the middle.
* The **red dashed line (Full Attention)** is generally the highest of the three, but again, the separation is minimal.
* The lines are so close that at many points, especially beyond Position 15K, the markers overlap significantly.
### Key Observations
1. **Uniform Decay Pattern:** The primary observation is the nearly identical performance trajectory of all three methods. The choice between MoBA, Full Attention, or their hybrid appears to have a negligible impact on the LM Loss vs. Position curve in this specific evaluation.
2. **Steep Initial Improvement:** The most significant reduction in loss occurs within the first 10,000 positions, after which the curves flatten into a long tail of gradual improvement.
3. **Minimal Differentiation:** While the `MoBA/Full Hybrid` (green) line is visually the lowest, the practical difference between the three methods is extremely small, likely within a margin of error for such measurements. The lines converge further as position increases.
### Interpretation
This chart suggests that for the task or model being evaluated, the core attention mechanism (whether it's the "Full Attention" baseline, the "MoBA" variant, or a hybrid) is not the dominant factor influencing how language model loss evolves with sequence position. The universal decay pattern indicates that all tested methods are equally effective at capturing the necessary contextual information to reduce prediction error as the sequence grows.
The steep initial drop implies that the most critical contextual dependencies for the model are established relatively early in the sequence. The long, flat tail suggests that beyond a certain context length (~10K-15K tokens), adding more position provides diminishing returns in terms of loss reduction for this specific setup.
From a technical standpoint, the key takeaway is the **robustness of the loss-position relationship** across these architectural variants. If the goal is to optimize LM Loss with respect to sequence position, efforts might be better directed toward other factors (e.g., data quality, training regimen, or model scale) rather than fine-tuning between these specific attention mechanisms, as they yield functionally equivalent results in this metric. The chart serves as evidence that MoBA and its hybrid are viable alternatives to Full Attention, achieving comparable performance.