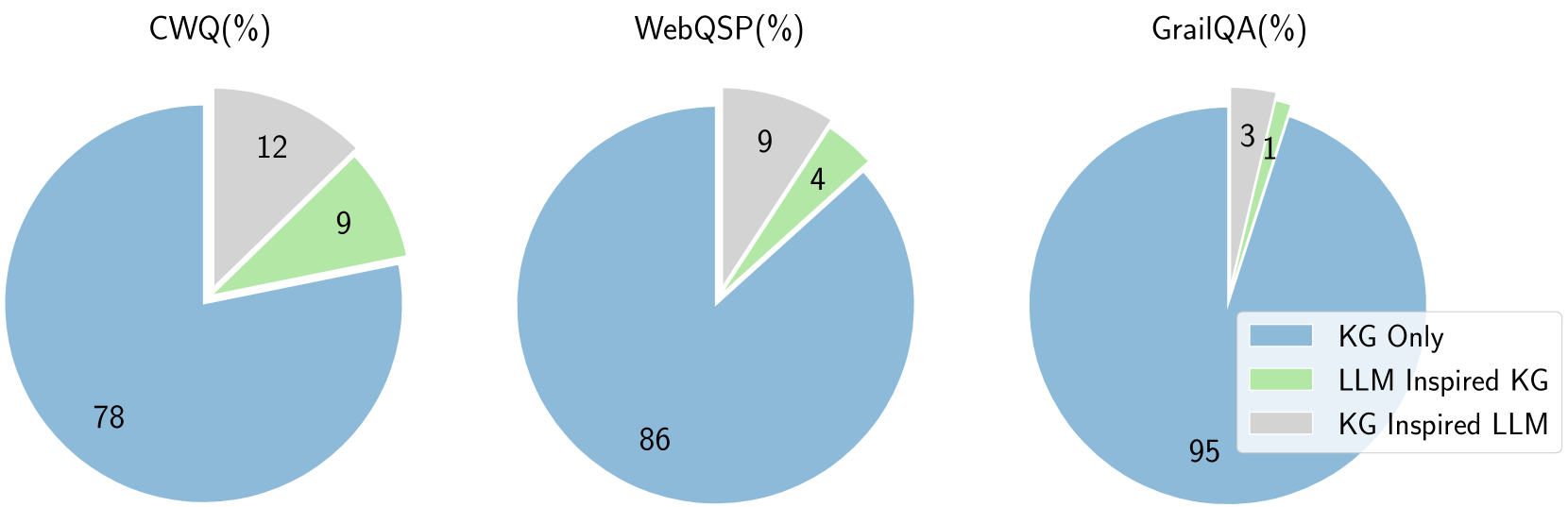
## Pie Charts: Knowledge Graph (KG) Approaches in QA Systems
### Overview
The image contains three pie charts comparing the distribution of three knowledge graph (KG) approaches across three QA systems: CWQ(%), WebQSP(%), and GrailQA(%). Each chart uses three color-coded segments to represent:
- **KG Only** (blue)
- **LLM Inspired KG** (green)
- **KG Inspired LLM** (gray)
### Components/Axes
- **Legend**: Located in the top-right corner, with color-coded labels:
- Blue: KG Only
- Green: LLM Inspired KG
- Gray: KG Inspired LLM
- **Chart Labels**:
- Top-left: "CWQ(%)"
- Center: "WebQSP(%)"
- Right: "GrailQA(%)"
- **Segment Values**: Percentages are explicitly labeled within each pie chart segment.
### Detailed Analysis
#### CWQ(%)
- **KG Only**: 78% (blue, largest segment)
- **LLM Inspired KG**: 9% (green, smallest segment)
- **KG Inspired LLM**: 12% (gray, medium segment)
#### WebQSP(%)
- **KG Only**: 86% (blue, largest segment)
- **LLM Inspired KG**: 4% (green, smallest segment)
- **KG Inspired LLM**: 9% (gray, medium segment)
#### GrailQA(%)
- **KG Only**: 95% (blue, largest segment)
- **LLM Inspired KG**: 1% (green, smallest segment)
- **KG Inspired LLM**: 3% (gray, smallest non-green segment)
### Key Observations
1. **Dominance of KG Only**: Across all three QA systems, the "KG Only" approach consistently holds the largest share:
- CWQ: 78%
- WebQSP: 86%
- GrailQA: 95%
2. **LLM Inspired KG Decline**: The "LLM Inspired KG" approach shows decreasing adoption:
- Largest in CWQ (9%)
- Smallest in GrailQA (1%)
3. **KG Inspired LLM Variability**: The "KG Inspired LLM" approach has moderate adoption in CWQ (12%) but minimal in GrailQA (3%).
### Interpretation
The data suggests a strong reliance on traditional **KG Only** methods across all QA systems, with GrailQA(%) being the most dependent on this approach. The declining share of **LLM Inspired KG** in GrailQA(%) (1%) indicates a potential shift away from hybrid LLM-KG integration in this system. Meanwhile, **KG Inspired LLM** shows inconsistent adoption, peaking in CWQ(%) (12%) but nearly absent in GrailQA(%) (3%). This could reflect differing design philosophies or evaluation criteria between the QA systems. The minimal presence of LLM-inspired approaches in GrailQA(%) might imply a focus on pure KG-based reasoning in that context.